IBM开发了一个新的机器学习库Snap ML,在测试中,相比 TensorFlow,Snap ML 获得相同的损失,但速度却快了 46 倍。
IBM 研究室的一个团队在过去两年开发了一个新的机器学习库Snap ML(IBM Snap Machine Learning)。之所以把它叫作 Snap,是因为他们相信用它来训练模型也就是弹指一挥间的事。这个机器学习库提供了非常快的训练速度,可以在现代 CPU 或 GPU 系统上训练主流的机器学习模型,或者在有新数据可用时保证已有模型的速度保持在线速水平(也就是网络能够支持的最快速度),这意味着更低的计算成本、更少的能源消耗和更快的开发速度。
与时间赛跑
数据的增长为机器学习和人工智能的大规模应用奠定了基础。大数据集为训练出丰富的模型提供了更多可能性,但当训练样本或特征达到数十亿的规模时,即使是训练最简单的模型也需要花费很长时间。在为关键应用(如天气预报和金融欺诈检测)研究、开发和部署大规模的机器学习模型时,过长的时间周期将成为严重障碍。
Snap ML 适用于多种场景。首先是拥有大量数据的应用程序,在这种场景下,需要解决训练时间瓶颈问题。其次是实时或近实时的应用程序,在这种场景下,模型会快速发生变更,同样对训练速度提出了很高的要求。第三个是集成学习(Ensemble Learning)领域。众所周知,现如今要想在数据科学领域的竞争中胜出,很大程度上要依赖大型的模型群组。为了设计出有竞争力的模型群组,数据科学家通常需要花费大量的时间去尝试各种模型组合和大量的超参数。在这种情况下,只有把训练速度提升一个数量级,才有可能加快研发速度,以便在竞争中胜出。
机器学习的效率、结果和洞见对于大大小小的企业来说都至关重要,而机器学习需要消耗大量的计算资源。计算资源的成本在持续攀升,所以对于企业来说,时间就是金钱。
Snap ML 采用最先进的算法和最优的系统设计,充分利用硬件资源,从而提供了更快的训练速度。Snap ML 的三个主要特性如下:
-
分布式训练:Snap ML 是一个可以自由伸缩的数据并行框架,训练数据集可以超出单台机器的内存容量,这对于大型应用程序来说至关重要。
-
GPU 加速:Snap ML 实现了一些特殊的程序,可以充分利用 GPU 的并行特性,同时在 GPU 内存中保留数据,减少数据传输开销。
-
稀疏数据结构:大部分机器学习数据集都是稀疏的,为此,他们对稀疏数据结构的相关算法进行了优化。
万亿级别的基准测试
由 Criteo 实验室发布的广告点击日志训练数据集包含了 40 亿个训练样本,每个样本都有一个“标签”和一组相关的匿名特征,其中标签用于标识样本是否由用户点击在线广告所生成。基于这组数据集进行机器学习,可以预测出新用户是否有可能点击某个广告。这个数据集是目前公开发布的最大的可用数据集之一,带有 24 天广告数据,平均每天包含 1 亿 6 千万个训练样本。
Snap ML 团队将 Snap ML 部署在 IBM Power System AC922 服务器上,每台服务器配备了 4 个 NVIDIA Tesla V100 GPU 和两个 Power9 CPU,它们通过 NVLINK 2.0 接口与主机连接,而服务器之间则通过无限带宽网络进行通信。他们在这些服务器上训练了一个逻辑回归分类器,时间为 91.5 秒,损失为 0.1292。
2017 年 2 月,谷歌花了 70 分钟在他们的云平台上使用 TensorFlow 训练同样的数据集。而且,他们使用了 60 台工作机和 29 台参数机。相比 TensorFlow,Snap ML 获得相同的损失,但速度却快了 46 倍。
在训练过程中需要解决的一个主要技术问题是,如何将那么大的数据集塞进 GPU 内存中。因为数据集太大,GPU 内存又很小,在训练过程中就需要不断地将数据移进移出 GPU 内存。为了分析 GPU 内核和数据拷贝分别花了多少时间,他们使用了数据集的一小部分进行测试,只选取了 2 亿个训练样本,并分别在两种硬件配置上运行:
-
配备 1 个 NVIDIA Tesla V100 GPU 和 Xeon Gold 6150 2.70GHz CPU 的服务器,使用了 PCI Gen 3 接口。
-
配备 4 个 NVIDIA Tesla V100 GPU 和 IBM Power System AC922 的服务器,使用了 NVLINK 2.0 接口。
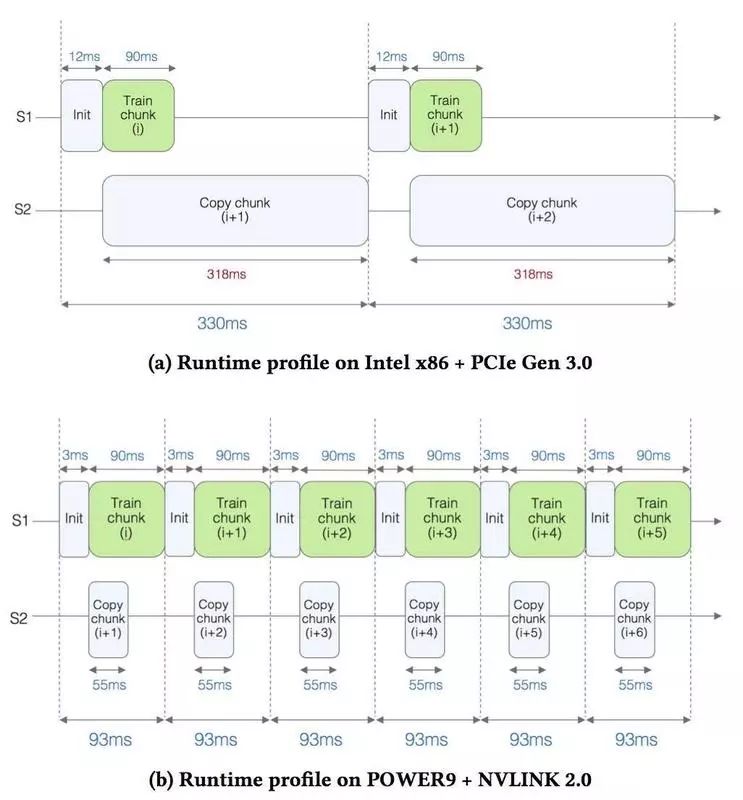
上图(a)展示的是第一种配置的运行情况。图中有 S1 和 S2 两条线。S1 是实际用于训练的时间,可以看到,每个数据块的训练时间大约为 90 毫秒。S2 是用于拷贝数据的时间,从图中可以看到,拷贝数据需要耗费 318 毫秒。这么看来,拷贝数据是训练的瓶颈所在。
上图(b)展示的是第二种配置的运行情况。可以看到,因为 NVLINK 2.0 接口提供了更大的带宽,用于拷贝数据的时间降到了 55 毫秒,所以整体速度提升了 3.5 倍。
Snap ML 系统简析
Snap ML 实现了多个层级的并行,以便在集群的多个节点上分摊工作负载,充分利用加速器单元和计算单元的多核并行能力。
第一层并行

第一层并行是指跨集群多个工作节点运行。训练数据分布在多个工作节点上,通过网络接口连接到一起。因为有了这种数据并行能力,才能够打破单台设备的内存限制,训练大规模的数据集。
第二层并行
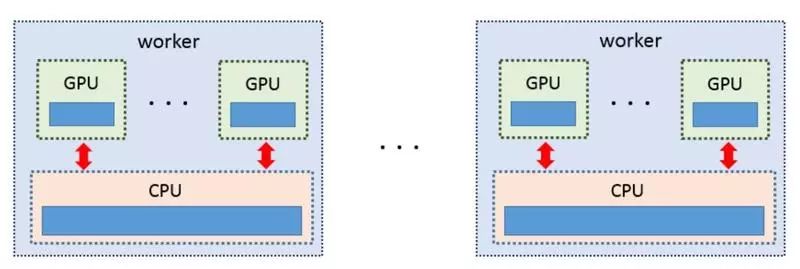
在每个工作节点上,可以通过将工作负载分摊给主机和加速器单元来获得并行能力。不同的工作负载可以同时被执行,工作节点的硬件资源得到了充分利用。
第三层并行
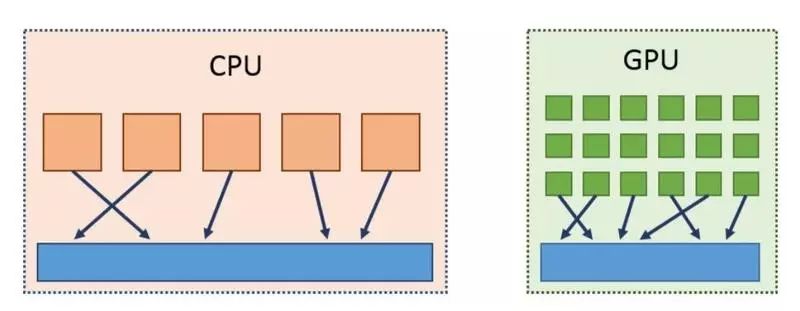
为了更进一步有效利用计算资源,Snap ML 实现了一些特殊的程序,可以充分利用现代 GPU 的并行能力,同时也开发了一些多线程代码,用于处理 CPU 的工作负载,这就实现了第三个层级的并行。
性能评测
研究人员对 Snap ML 进行了性能评测,让它运行在不同配置的硬件上,并将它与 sklearn、TensorFlow 和 Apache Spark 进行对比。
评测所使用的机器学习应用程序是互联网界较为热门的点击率预测(Click-Through Rate Prediction,CTR)。CTR 是一种大规模的二元分类应用,基于一系列匿名特征来预测一个用户是否会点击一个广告。
评测所使用的数据集是由 Criteo 提供的广告点击数据集,他们使用前 23 天的数据进行模型训练,然后使用最后一天的数据进行性能测试。数据集的详细信息如下表所示:

单节点性能
单节点测试主要是要测出 Snap ML 在单台服务器上运行的性能,测试内容是训练一个逻辑回归分类器,并使用相同的正规化参数(λ = 10),然后比较 Snap ML 与 sklearn 和 TensorFlow 之间的差别。测试使用的是 criteo-kaggle 数据集,它的大小是 11GB,可以塞进单台机器或单个 GPU 的内存里。服务器是 IBM Power System AC922,配备了 4 个 NVIDIA Tesla V100 GPU,并使用了 NVLINK 2.0 接口,不过在实际运行中只用了其中的一个 GPU。结果如下图所示。
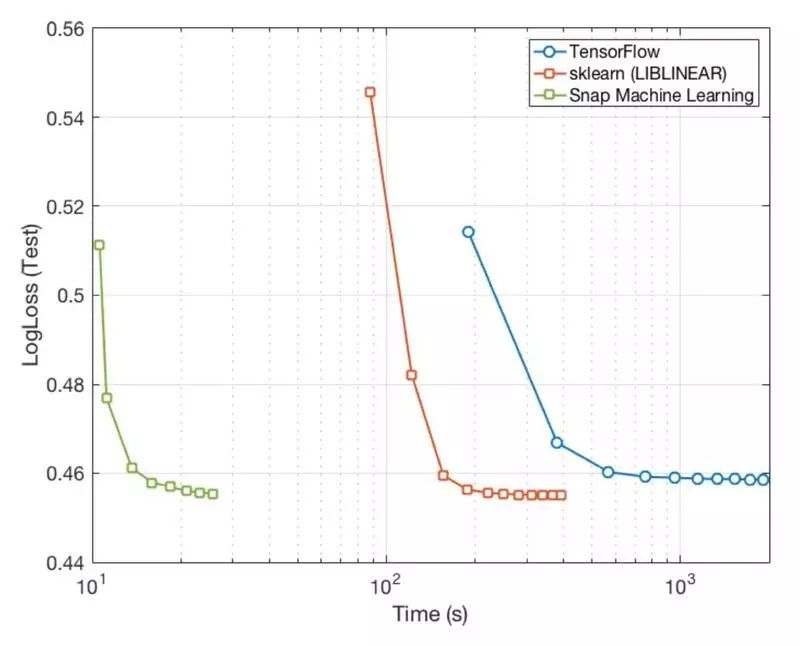
从图中可以看出,TensorFlow 使用了大约 500 秒,而 sklearn 只使用了 200 秒左右。这个可能是因为 sklearn 把全部数据集都装入内存,而 TensorFlow 则是每次从磁盘上读取一批数据。当然,成绩最好的是 Snap ML,只花了大约 20 秒,比前两个框架快一个数量级,这要归功于 Snap ML 团队开发的 GPU 处理程序。
多节点性能
多节点测试主要是要测出 Snap ML 在集群上训练模型的性能,总共进行了两次测试。在第一次测试中,本地训练数据可以完全塞进 GPU 内存中,他们分别训练了一个线性回归模型(Linear Regression)和一个支持向量机模型(SVM),并将结果与 Spark MLLib 进行对比。第二次主要测试在本地训练数据无法完全塞进 GPU 内存的情况下,Snap ML 将会有怎样的表现。多节点测试使用的是 criteo-1b 数据集,它的大小是 274GB,普通的单台机器无法把它全部塞进内存。
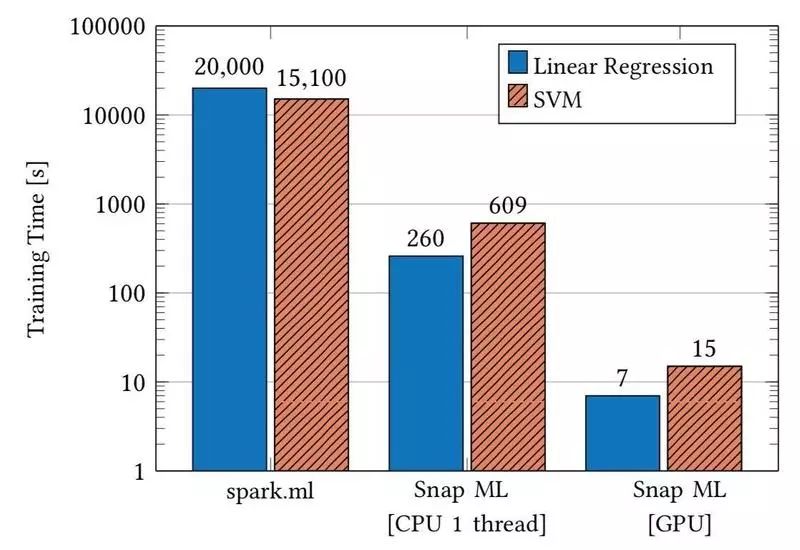
从上图可以看出,在第一次测试中,在不启用 GPU 加速的情况下训练两种模型,Snap ML 均比 Spark MLLib 快上不止一个数量级:训练线性回归模型快 77 倍,训练支持向量机模型快 24 倍。而在启用 GPU 加速的情况下,训练线性回归模型快 2800 倍,训练支持向量机模型快 1000 倍。
第二次测试的内容是训练一个 SVM 分类器。训练集群包含了 4 个节点,每个节点配备了 2 个 NVIDIA GTX 1080 Ti GPU。这种 GPU 有 11GB 内存,其中 8G 可用于存储数据。测试使用的二进制数据集 criteo-1b 大小为 98GB,无法全部塞进单台服务器的 GPU 内存中。为了充分利用每个节点的 GPU,他们结合使用了 DuHL 和 CoCoA。
下图展示的是启用 GPU 加速的训练时间、使用单线程 CPU 进行训练的时间,以及使用 Snap ML 提供的多线程 CPU 程序进行训练的时间。

从图中可以看出,在启用 GPU 加速的情况下,即使训练数据无法完全塞进 GPU 内存,因为使用了 DuHL,其训练速度比使用 CPU 的单线程或多线程都快了一个数量级。
大规模基准测试
这次测试使用了全部的 42 亿个训练样本,并把 Snap ML 部署在 IBM Power System AC922 服务器上,每台服务器配备了 4 个 NVIDIA Tesla V100 GPU。测试内容是训练一个逻辑回归模型,并分别与 TensorFlow、LIBLINEAR、Vowpal Wabbit 和 Spark MLLib 已经公布的测试结果进行对比。
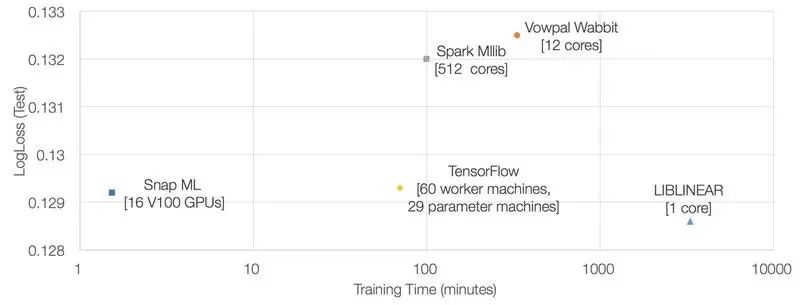
从上图可以看出,Snap ML 的训练速度比之前最好的成绩(TensorFlow)快 46 倍。
如果读者想要进一步了解 Snap ML 的实现原理和算法细节,可以阅读其研究论文:
https://arxiv.org/pdf/1803.06333.pdf
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。






























