同事欲从数据库中将数据导出,使用mysqldump命令,但是发现备注和字段不同步的问题,结果中总是出现:备注或者字段出现乱码,无论如何设置字符编码也无效,总是不同步。这也勾起了我的兴趣,花了大概一天时间做实验,弄明白了其中的一些机理。【事件现象】mys
同事欲从数据库中将数据导出,使用mysqldump命令,但是发现备注和字段不同步的问题,结果中总是出现:备注或者字段出现乱码,无论如何设置字符编码也无效,总是不同步。这也勾起了我的兴趣,花了大概一天时间做实验,弄明白了其中的一些机理。
【事件现象】
mysqldump --default-character-set='latin1' -u test --password=test1234 TypeList > test.sql选出的数据有如下特点:
1. comment部分的中文是经过一次utf8转换的gbk编码
2. 数据表中列的值是gbk编码(当初入库的时候是gbk编码)
mysqldump --default-character-set='gbk' -u test --password=test1234 TypeList > test.sql这时的数据特点:
1. comment部分的中文是经过一次utf8转换的gbk编码
2. 数据表中列的值是经过一次:latin1->gbk 乱码(入库的时候是gbk的编码,此时相当于在此基础上又做了一次latin1转gbk的计算)
【现象总结】
1. default-charater-set的值不影响comment部分
2. default-charater-set的值影响数据表列值
【原因】
经过差mysql手册和Google的结论,发现在mysql中,字符编码的转换规则如图:
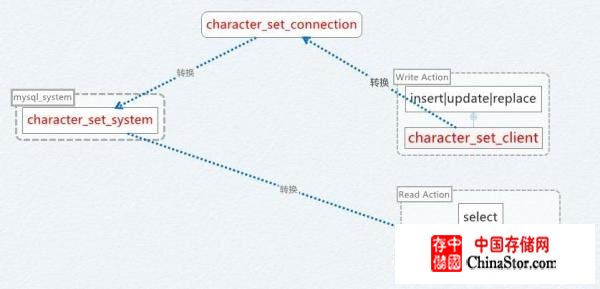
上图可以看到,mysql元字符集为utf8,即所有数据编码最终被转换为utf8来执行计算。数据从客户端到mysql存入时,会经历两次字符编码转换,一次是:从character_set_client到character_set_connection的转换,一次是从character_set_connection到character_set_system的转换。故,当时入库的数据是gbk的中文字,经历了从:latin1->utf8的转换过程。
取出的时候,普通的结果执行一次:character_set_system->charater_set_results的转换,(从效果上讲,character_set_connection可以省略)。
然而,这里出现了一个bug:mysqldump的时候,comment作为元数据直接被返回,没有对齐进行字符编码转换!这也就是为什么comment编码与列编码不同的原因。
【修正后的结果】
因此,我们使用命令:
mysqldump --default-character-set='utf8' -u test --password=test1234 TypeList > test.sql取出的数据编码一致,然后在执行:
iconv -f utf8 -t latin1 -o t.sql test.sql
获得最终的gbk版本的数据。
【启示】
若要保证数据的一致性,则保证:character_set_results和character_set_client一致,但是个人建议将:character_set_results、character_set_client、php文件编码一致,这样在系统中,方便命令行的读取时编码的一致性。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。










