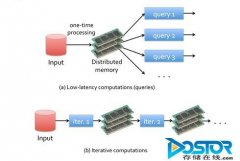
使用Kmeans数据的对比hadoop和spark。读取HDFS上的block到内存,每个block转化为RDD,里面包含vector。然后对RDD进行map操作,抽取每个vector(point)对应的类号,输出(K,V)为(class,(Point,1)),组成新的RDD。
1. Kmeans
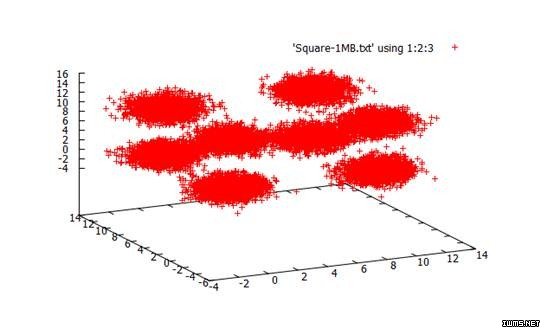
数据:自己产生的三维数据,分别围绕正方形的8个顶点
{0, 0, 0}, {0, 10, 0}, {0, 0, 10}, {0, 10, 10},
{10, 0, 0}, {10, 0, 10}, {10, 10, 0}, {10, 10, 10}
|
Point number |
189,918,082 (1亿9千万个三维点) |
|
Capacity |
10GB |
|
HDFS Location |
/user/LijieXu/Kmeans/Square-10GB.txt |
程序逻辑:
|
读取HDFS上的block到内存,每个block转化为RDD,里面包含vector。 然后对RDD进行map操作,抽取每个vector(point)对应的类号,输出(K,V)为(class,(Point,1)),组成新的RDD。 然后再reduce之前,对每个新的RDD进行combine,在RDD内部算出每个class的中心和。使得每个RDD的输出只有最多K个KV对。 最后进行reduce得到新的RDD(内容的Key是class,Value是中心和,再经过map后得到最后的中心。 |
先上传到HDFS上,然后在Master上运行
|
root@master:/opt/spark# ./run spark.examples.SparkKMeans master@master:5050 hdfs://master:9000/user/LijieXu/Kmeans/Square-10GB.txt 8 2.0 |
迭代执行Kmeans算法。
一共160个task。(160 * 64MB = 10GB)
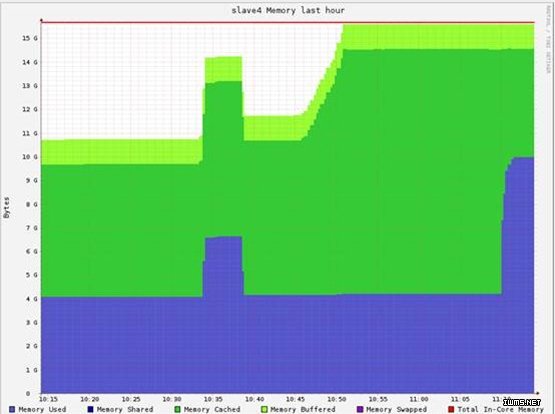
利用了32个CPU cores,18.9GB的内存。
每个机器的内存消耗为4.5GB (共40GB)(本身points数据10GB*2,Map后中间数据(K, V) => (int, (vector, 1)) (大概10GB)
最后结果:
|
0.505246194 s Final centers: Map(5 -> (13.997101228817169, 9.208875044622895, -2.494072457488311), 8 -> (-2.33522333047955, 9.128892414676326, 1.7923150585737604), 7 -> (8.658031587043952, 2.162306996983008, 17.670646829079146), 3 -> (11.530154433698268, 0.17834347219956842, 9.224352885937776), 4 -> (12.722903153986868, 8.812883284216143, 0.6564509961064319), 1 -> (6.458644369071984, 11.345681702383024, 7.041924994173552), 6 -> (12.887793408866614, -1.5189406469928937, 9.526393664105957), 2 -> (2.3345459304412164, 2.0173098597285533, 1.4772489989976143)) |
50MB/s 10GB => 3.5min
10MB/s 10GB => 15min
在20GB的数据上测试|
Point number |
377,370,313 (3亿7千万个三维点) |
|
Capacity |
20GB |
|
HDFS Location |
/user/LijieXu/Kmeans/Square-20GB.txt |
运行测试命令:
|
root@master:/opt/spark# ./run spark.examples.SparkKMeans master@master:5050 hdfs://master:9000/user/LijieXu/Kmeans/Square-20GB.txt 8 2.0 | tee mylogs/sqaure-20GB-kmeans.log |
得到聚类结果:
|
Final centers: Map(5 -> (-0.47785701742763115, -1.5901830956323306, -0.18453046159033773), 8 -> (1.1073911553593858, 9.051671594514225, -0.44722211311446924), 7 -> (1.4960397239284795, 10.173412443492643, -1.7932911100570954), 3 -> (-1.4771114031182642, 9.046878176063172, -2.4747981387714444), 4 -> (-0.2796747780312184, 0.06910629855122015, 10.268115903887612), 1 -> (10.467618592186486, -1.168580362309453, -1.0462842137817263), 6 -> (0.7569895433952736, 0.8615441990490469, 9.552726007309518), 2 -> (10.807948500515304, -0.5368803187391366, 0.04258123037074164)) |
基本就是8个中心点
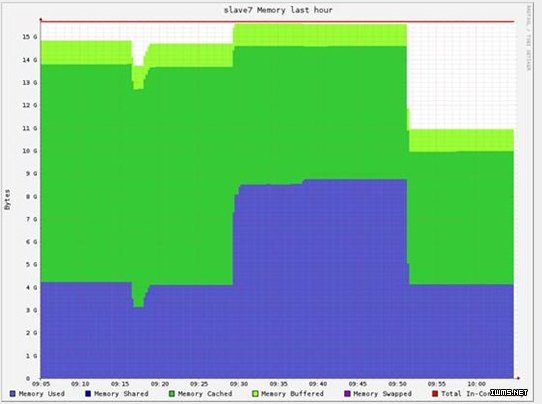
内存消耗:(每个节点大约5.8GB),共50GB左右。
内存分析:
20GB原始数据,20GB的Map输出
|
迭代次数 |
时间 |
|
1 |
108 s |
|
2 |
0.93 s |
12/06/05 11:11:08 INFO spark.CacheTracker: Looking for RDD partition 2:302
12/06/05 11:11:08 INFO spark.CacheTracker: Found partition in cache!
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。