该研究使用超维计算算法不仅简化了推理,而且简化了训练。该方法克服了神经网络的敏感性,大大简化了训练。
PCM专家Ron Neale探索了如何使用PCM来使AI和ML应用受益。尽管AI是The Memory Guy博客的新功能,但存储芯片与某些AI应用(尤其是神经网络)之间有着惊人的相似性。
Neale在这篇文章中研究了IBM在Nature Electronics上发表的最新研究成果,该研究使用超维计算算法不仅简化了推理,而且简化了训练。该方法克服了神经网络的敏感性,大大简化了训练,同时通过仅一次写入内存来消除磨损问题,即使内存大小很小。
过去,IBM已应用PCM的特殊功能,这些功能允许内存中的乘法和加法功能解决压缩感测(CS)和稀疏信号恢复以及图像重建的问题[2],[3]。
这项最新工作建立在较早的工作基础上,并与一个完整的系统(可以视为三台计算机的堆栈)一起使用,其中PCM充当计算机和内存的双重角色,如下所示。
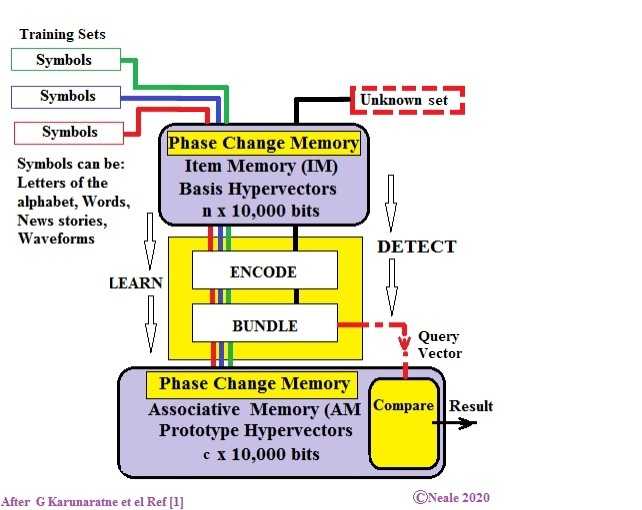
线性代数的魔力是识别或推理过程的核心,无论是字符,单词,波形等,线性代数的用途都是通过使用非常高维的矢量(10,000位)来实现清晰分隔的停车位。在多维向量空间中找到类,即对象的集合及其细微差别。
然后,属于未知类别的小样本可以使用基于PCM的相同过程在为该家庭或类别分配的多维向量空间中找到唯一位置,并成功进行识别,而不会造成混淆的风险。
在上图中,使用一系列训练集对系统进行了训练,这些训练集用红色,蓝色和绿色标识。我们在本文中使用的示例将是不同的语言,每种语言的训练集由多种语言中每种语言的大型文本文件组成。一旦对系统进行了训练,就可以处理右上角的未知字符集(在这种情况下,可能是这些语言之一的短文本字符串)可以确定其语言。
2个紫色框表示在其中执行内存处理的相变存储器(PCM)。该顶部内存称为项目内存,它存储基础超向量。底部存储器称为关联存储器,它存储原型超向量。在这两者之间是一个黄色逻辑块,它执行一个称为捆绑的任务。所有这些都将在本博客文章的稍后部分进行解释。
该图的简短说明是,通过内存中处理和捆绑对每个训练集执行一个过程,并且该过程的结果存储在底部的关联存储器中。现在已经对系统进行了训练,可以将未知集合进行相同的过程,并在关联内存中将其与其他集合进行比较,以确定哪个是最佳匹配。
10,000位字(也称为矢量)的使用产生了用于超维计算(HDC)的前缀“ Hyper”,作为对该系统中使用的方法的描述。
超维度计算超
维度计算并不是新事物,代数和复杂的概率数学已经在机器学习和识别中占有一席之地。类似的技术也已经用于数字通信中。实际上,在该文献中可以找到以多种方式对大脑及其根部进行建模的系统鲁棒性,所有这些都需要大量常规计算开销。
新颖的是在系统级别上证明了PCM提供内存中计算以减轻总体计算工作量的能力,并借助某些IBM创新的矢量处理快捷方式进一步加以了支持。
内存起着存储设备和计算机的正常作用。PCM允许简单地将欧姆定律用于乘法,将基尔霍夫定律用于加法,以执行复杂的统计计算。PCM的电阻在受到输入电压的作用下提供电流形式的乘积(I = V x 1 / R),并且当许多PCM单元连接到公共点时,输出就是输入电流的总和。神经网络通常以这种方式实现。这是基于PCM的HDC的简单部分。从那里开始,它变得更加复杂,并进入多维超向量空间的世界。
HDC识别的先前实现需要频繁更新内存位置,从而导致对基于非易失性内存的系统的磨损的担忧。IBM研究团队能够找到数学解决方法,将所有内存位置限制为只能写入一次。所有后续的内存访问均被读取。此外,训练和识别都在一次通过中执行,从而在提高速度的同时降低了功耗。
HDC方法的另一个好处是它使用极其简单的数学运算,其中所有操作数都由一个位组成。大量的操作数弥补了缺少任何单个操作数的精度的不足。这有点类似于可以通过大量微小的黑白点组成高质量的灰度照片的方式。即使丢失了一些点,图片仍然可以识别。稍后我们将看到该系统的两个存储器之一如何执行与神经网络相对类似的功能,但是通过使用单位精度而不是多位存储元件,系统对位元性能的变化变得不那么敏感。 。
PCM设备结构
作为PCM专家,我自然对学习IBM在此设计中使用哪种PCM感兴趣。
用于这项最新工作的内存阵列每个都包含300万个PCM单元,与IBM在较早的内存计算演示中所使用的相同。有源存储材料采用在90nm CMOS技术上制造的PCM单元掺杂了Ge 2 Sb 2 Te 5(d-GST),采用所谓的“锁孔”工艺。
底部电极的半径为20nm,d-GST的厚度为100nm,上部电极的半径为100nm。
IBM似乎没有任何计划以存储产品的形式将其PCM阵列提供给第三方。那些希望应用超维计算技术的人目前将不得不依靠其他资源,甚至依赖于其他NVM技术,例如ReRAM或MRAM电阻设备。
简单的问题
让我们看一下IBM团队解决的最简单的问题。它正在分析一个短句形式的单词(包括空格)样本,并确定其所属的语言。为了简化起见,我们假设所有语言都使用相似的字母。解决该特定问题的完整流程图如下所示。
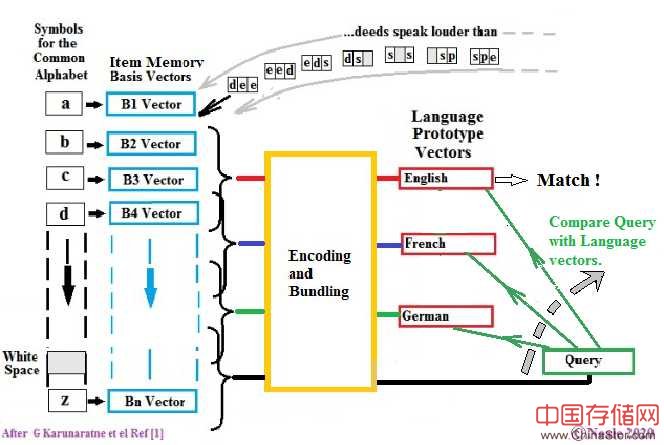
该图描述了一个处理序列,该序列将每种语言的特殊特性封装到一个10,000个元素的向量中。此实验的特点是每种语言特有的字母分组。(例如,英语比法语或德语多使用“ th”组合,而法语比其他多使用“ qu”,德语多使用“ ch”。)
在顶部输入字符流:“行动胜于雄辩。” 该系统旨在分析字母组,因此该图以三个一组的形式显示了该字符串中的字母。
我将使用许多流行语简要解释图表,这些流行语将在下文中定义。
每个字母都充当包含“基本超向量”的内存的地址。将当前字母的基础超向量与该组中其他字母的基础超向量组合,并将此组合发送到编码和捆绑机制。然后将所有3个字母的组合捆绑(定义如下)到“原型超向量”中,以存储在“关联内存”中。
具有10,000个元素的原型超向量没有数值-它更多是承载信息的元素(位)的模式。更准确地说,它代表了多维空间中唯一且明显不同的点。大量的维数意味着在识别步骤中,可能需要从样品中识别出图案的某些部分,而仍然可以快速准确地进行识别。
训练完系统后,可以使用与训练文本相同的方式处理未知语言的文本字符串,以生成“查询超向量”。然后将此查询超向量与所有原型超向量进行比较,以确定哪个原型超向量与查询最相似。
逐步功能
进入多维向量空间的第一步涉及创建所谓的“基础超向量”。10,000位基础超向量必须是相等数目的1和0的随机序列,以支持HyperDimension Computing独特的数学形式。它们被称为基础超向量,因为它们是设备中所有操作的起点。这些基础超向量存储在项目存储器中,并在产品生命周期内保持不变。
下一步是为每种语言创建一个“原型超向量”。分析每种语言的成千上万个句子,以找到3种字母的序列,这些序列是特定语言的特征。训练文本中的每个3个字母的序列都会根据基础超向量生成10,000位代码。该系统旨在为相同的三个字母序列的每个实例产生相同的10,000位代码。然后,将此代码逐位添加到其前面所有3个字母序列的10,000位代码中。训练完成后,将针对阈值测试这10,000个总和,以产生大于阈值的数字“ 1”,否则生成“ 0”,从而产生该语言独有的10,000位原型超向量。
创建原型超向量
让我们看一下如何创建这个有趣的向量。
基础超向量被加载到称为项目存储器(IM)的PCM阵列中,如本文第一幅图所示。项存储器配置为N个单词(公共字母中的字母数,加上一个空格),每个单词均由10,000位基本超向量组成,每个单词如前所述,由一组相等但随机的1s和0s。项目存储器的内容永不变。
当字符到达时(显示在第二个图形的顶部的弧形中),每个字符都选择合适的基础超向量,然后将其与相邻两个字母的基础超向量混合以形成代表该序列的三字母组。研究人员选择使用内存中的计算功能简化此计算。如前所述,将为相同的三个字母序列的每个实例生成相同的10,000位代码
然后将整个训练集的这些序列添加到捆绑机制中以产生总和,然后将其与阈值进行比较以产生原型超向量的位。在此过程中,所有向量均为10,000个元素超向量。
考虑一种语言的原型超向量的一种方法是,每个位代表来自相同语言的类似生成的向量在相同位位置具有“ 1”的可能性。这是因为该语言的三个字母的组通常会在该位位置生成一个带有“ 1”的超向量。如果原型超向量在该位位置具有“ 1”,则其他类似生成的超向量更有可能具有“ 1”,并且如果原型超向量在另一个位位置具有“ 0”,则类似生成的超向量为该位置更可能具有“ 0”。
训练序列成为大型训练集的单一遍历。例如,较长的英语文本流将通过此过程运行,以生成单个英语原型超向量。一旦生成了该原型超向量,就将其存储在另一个名为“关联存储器”的PCM存储器中,该地址已被留出以代表英语。其他地址将用于存储代表其他语言的原型超向量。
然后针对每种语言重复此过程,生成代表该语言的原型超向量,并将该语言的原型超向量存储到已为该语言保留的关联存储器中的地址中。
匹配未知文本:查询超向量
在处理完所有训练语言之后,可以使用原型超向量确定新文本字符串的语言。这是如何做:
尽管10,000位原型超向量似乎是“ 1s”和“ 0s”的随机分布,但是在该向量内是其所代表语言所独有的统计模式。如果使用与原型超向量相同的方式处理来自相同语言的新文本字符串,则它应该共享相似的属性,尽管不太可能是相同的。
这些向量的长度允许即使某些位丢失,也很有可能将原型超向量与新文本字符串的超向量正确匹配,这称为“查询超向量”。它是根据比训练集更短的文本序列创建的,不一定包含所有序列,甚至不必包含字母表的所有字母。
在操作中,未知语言的文本字符串将被处理为查询超向量。然后针对每种训练过的语言,将其与原型超向量进行比较,然后系统确定最接近的拟合形式。(接下来我将解释如何。)系统会回答以下问题:“这个新的文本字符串最类似于哪种语言?”
在很大程度上,成功的可能性增加了,因为每种语言原型超向量在多维向量空间中都与其他语言相距甚远,以至于不可能出现识别错误。重要的功能是,将查询超向量和原型超向量之间的统计链接进行比较时,成功率很高。
将查询与原型
匹配通过计算超空间中查询彼此之间的接近程度,可以将查询超向量与原型超向量进行匹配。由于所有维度都是单位变量,因此此计算非常简单,归结为确定它们共有多少位。沿两个位串的每个点上的“ 1s”和“ 0s”之间的重合越多,它们彼此之间就越相似。
如果在尺寸较小的空间中以多位值测量距离,则形式化计算将非常费力,并且将需要其他电路元件。但是,由于比较的向量具有相同数量的数字,并且由于这些数字都是二进制数字,因此IBM找到了一个简洁的捷径,或者简化了距离方程式的计算复杂度。本质上,超向量可能比更多传统方法具有更多的位,但是数学变得更简单,并且这种简单性掩盖了位计数的增加。
就像使用神经网络一样,通过计算查询和原型超向量的点积,将查询超向量与所有原型超向量进行比较,这是一次操作。点积是两个向量的相应元素的乘积,然后是这些乘积的加法。
图中显示了
其中执行点积的联想存储器的一小部分。
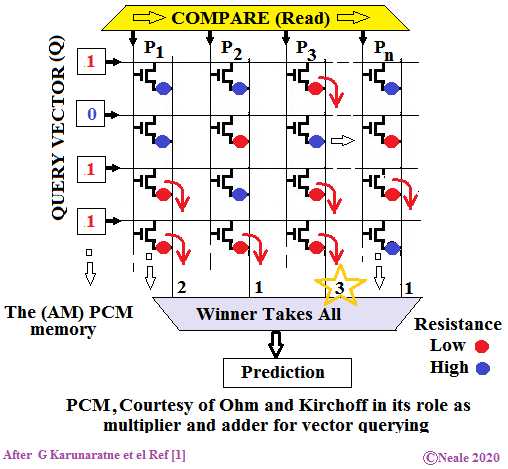
查询超向量应用于该图中的水平线,原型超向量(图中的P1,P2,P3…Pn)垂直位于PCM位单元中,分别显示为红色和蓝色点-红色点代表一个低阻抗或“ 1”,蓝点表示高阻抗或“ 0”。查询超向量中的任何为1的位都将打开该行中的晶体管。在查询超向量和原型超向量都具有“ 1”的任何位位置,晶体管和PCM位单元都将允许电流流动,如红色箭头所示,并且该电流将被馈入到垂线。这个简单的动作由欧姆定律启用,执行点积所需的乘法。
然后,基尔霍夫定律将起作用以提供垂直线上的电流之和,从而提供乘积之和以完成点积。乘法和加法在单个操作中执行。在每条垂直线中产生不同的电流,并在每条线的底部表示。原型超向量与输入查询超向量更接近的行将具有较高的电流,而其他行将具有较低的电流。
顶部的黄色框仅按顺序排列垂直线,以防止所有内容立即打开。
确定哪个原型Hypervector最接近查询Hypervector只是确定哪个垂直线具有最高电流的问题,这由获胜者通吃电路决定,最大电流确认匹配。
结果
该系统提供了很好的准确性,如下图所示,摘自研究人员的工作:
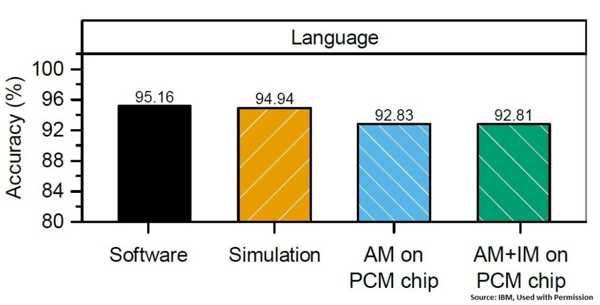
该图表比较了4种不同的试验:超维计算算法的全软件实施例,基于PCM的系统的模拟,在基于PCM的芯片上仅实现关联存储器的实施例以及两者项目存储器和关联存储器在PCM芯片上实现。尽管该软件实施例能够使用高精度数学运算,但是有趣的是,即使PCM受内部噪声的影响,并且点乘积中的电流会受到电阻变化的不利影响,但还是可以看到这两种PCM实现与其性能的接近程度。在PCM位单元和选择晶体管中。
在另一个对新闻故事进行分类的应用程序中,该方法也同样有效
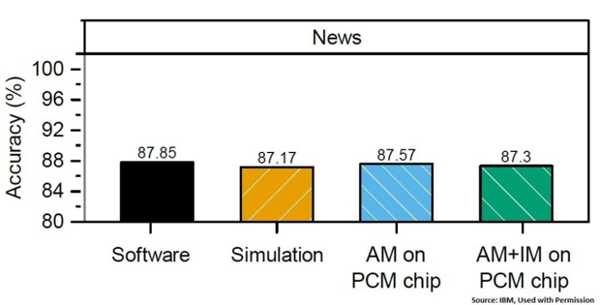
再次,尽管硬件面临问题,但PCM实施例与软件实施例相比还是非常有利的。
研究人员估计,使用更常规的CMOS而不是基于PCM的内存中计算的全硬件方法,每场比赛将消耗数十至数百倍的能量,并且所需的芯片面积将比其设计大数十倍。
使用PCM的单次查询方法无需复杂的多次尝试技术即可在不消耗功率和时间的情况下给出答案,这是基于PCM的内存计算的明显优势。通过将PCM与欧姆定律和基尔霍夫定律进行创新的混合来计算点积,便提供了一种一次性解决方案。
在一系列不同的测试中,使用内存计算的基于PCM的方法在准确性方面被证明可与传统的基于全软件的方法相媲美。对于基于统计的系统,结果是一种预测,因此准确性是成功的指标之一。
本文作者:PCM专家Ron Neale。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。


































