Google设计了一个名为Mesa的分布于全球的数据仓库系统,它能 实时处理海量数据,即使在数据中心断线后还能正常工作。
在过去几年里,谷歌的研究人员一直在致力于打造复杂且功能强大的新款data-warehousing system 数据仓库系统Mesa。这一系统源于谷歌的核心业务:互联网广告。
根据谷歌发布的一份最新研究报告显示,为了更好地为广告客户提供服务,同时满足公司内部需求,谷歌一直在收集特定广告的细节信息。这就要求该公司必须具备实时记录和处理这些信息的能力。
而Mesa恰恰能够大批量、接近实时地处理谷歌收集到的这些信息。谷歌研究人员在这份报告中表示:“Mesa能够处理数千兆字节的数据、每秒数百万行的更新以及每天数十亿查询请求。”
Mesa有可能为谷歌云计算平台Cloud Platform带来新的云服务。亚马逊云平台Web Services就拥有一个名为Redshift的数据存储服务,而微软Azure也能够降低云服务的价格且频繁发布新款云服务。因此,在与亚马逊和微软的较量中,Mesa有助于谷歌实现更加差异化的竞争优势。
谷歌此前曾经推出了数据分析利器Dremel查询系统,随后又在Dremel的基础上开发出了BigQuery企业级大数据分析平台。从结构上来说,研究人员采取了多种措施让Mesa不同于Dremel。而且,与Facebook开发的数据查询引擎Presto相比,Mesa也更具优势。
研究人员在报告中指出:“Mesa可以在多个数据中心之间同步拷贝数据。这种采取分散架构的云计算模式已经取得了成功,因为它能够有效应对数据和查询能力的增长需求。”
期待

今年9月在杭州举行的数据库学术会议VLDB 2014上,Google的工程副总Shivakumar Venkataraman与正在Google访问的UCSB教授、IEEE与ACM Fellow Divyakant Agrawal将做主题演讲,介绍Google的实时分析数据仓库Mesa。
延伸:以下内容来自CSDN:
Google最近发表了一篇有关大数据系统的论文,讨论了一个名为Mesa的分布于全球的数据仓库系统,它能 实时处理海量数据,即使在数据中心断线后还能正常工作。Google工程师将在下月于中国举行的超大型数据库会议上,提交一篇有关Mesa的论文。
本质上来说,Mesa是一个ACID式数据库(如果有人进行查询,就会得到相应数据),速度快,规模大,可靠性强。它被设计为处理与Google广告业务有关的需求 (服务内部用户,以及消费者的前端查询服务),但也能作为一般数据仓库系统,供其他用途。
Google早就拥有数据系统 Dremel,Facebook 和Twitter也拥有自己的系统,但Google 指出,这些系统一般只用作大容量数据装载,而不是像 Mesa那样即时处理数据。而且,目前的商业产品或产品系统均不能用来管理跨数据中心的重复数据,这些系统也并非基于云技术,灵活性也不强。它们对动态条款和资源置换的适应性也很弱,无法处理数据装载波动。
在先期公开的论文“Mesa:Geo-Replicated, NearReal-Time, ScalableData Warehousing”中这样描述Mesa的开发初衷和特点:
Mesa是一个高度可扩展的分析型数据仓库系统,用于存储Google互联网广告业务相关的关键衡量数据。Mesa的设计目的是满足一系列复杂而有挑战性的用户与系统需求,包括近实时的数据获取和查询、高可用性、可靠性、容错和(大规模数据与查询量的)可扩展性。Mesa可以应对P级数据,每秒处理数百万行更新,每天抓取数万亿行以支持数十亿查询。Mesa是跨多个数据中心异地复制的,即使整个数据中心故障,仍然能够以较低延迟返回一致和可重复的查询结果。
针对数分钟更新吞吐量、跨数据中心等等严苛需求,已有的商业数据仓库系统(处理周期往往以天和周来计算)和Google的解决方案包括BigTable、Megastore、Spanner和F1都无法满足要求。BigTable无法提供必要的原子性,Megastore、Spanner和F1无法满足峰值更新需求。此外,Google自己开发的Tenzing、Dremel,以及Twitter开发的Scribe、LinkedIn的Avatara、Facebook的Hive以及HadoopDB等Web规模数据仓库处理的都是批量负载。
论文中提到比较类似Mega的系统是Stonebreaker等开发、已被HP收购的Vertica,但缺乏跨数据中心的功能。其他相关工作中,Thrifty针对的数据量较小,且应用于多租户场景;Shark是内存计算;MaSM利用了闪存。
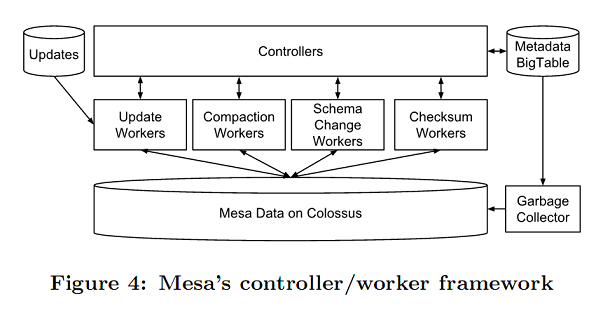
Mesa基于BigTable(元数据存储)和Colossus(数据文件),底层也用到了MapReduce(谁说Google好几年前就不用MR了?),所用的分布式同步协议基于Paxos。
controller/worker框架的架构如下:
查询处理框架:

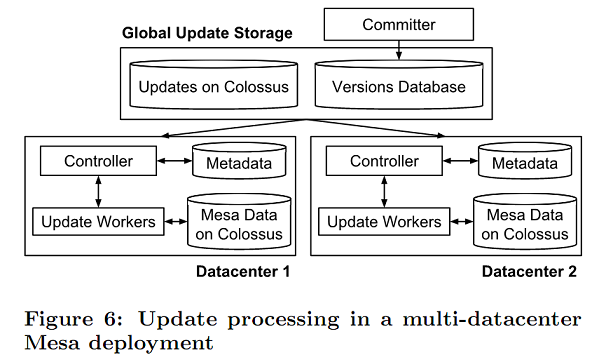
多数据中心的更新处理架构:
GigaOM的报道中提及,Hadoop社区的Doug Cutting等都在密切关注Google的新动向,Mesa如果有高质量的开源版本,也将非常受欢迎。当然,Google也很有可能像BigQuery之于Dremel那样,在云中提供Mesa类似功能。毕竟,Mesa的论文中也强调了,虽然是为Google数百亿美元的广告业务服务的,但Mesa是一个通用数据仓库解决方案。
另外,VLDB 2014其他已接受的论文都已公开了:http://vldb.org/2014/accepted_papers.html,大家可以各取所需。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。