第 1 部分: 与语言无关的 HTTP API 使用 Riak 的 HTTP 界面存储和检索数据 本文是由两部分组成的关于 Riak 的系列文章的第 1 部分,Riak 是 Amazon 的高可用性键值存储库,用 Erlang 编写且基于 Dynamo,是一种高度可扩展的分布式数据存储。本文将介绍 Riak
本文是由两部分组成的关于 Riak 的系列文章的第 1 部分,Riak 是 Amazon 的高可用性键值存储库,用 Erlang 编写且基于 Dynamo,是一种高度可扩展的分布式数据存储。本文将介绍 Riak 的基本知识以及如何使用 Riak 的 HTTP API 存储和检索内容。本文将探讨如何使用 Riak 的 Map/Reduce 框架执行分布式查询,如何使用链接定义对象之间的关系,以及如何使用 link walking 查询这些关系。
简介
典型的现代关系数据库在某些类型的应用程序中表现平平,难以满足如今的互联网应用程序的性能和可扩展性要求。因此,需要采用不同的方法。在过去几年中,一种新的数据存储类型变得非常流行,通常称为 NoSQL,因为它可以直接解决关系数据库的一些缺陷。Riak 就是这类数据存储类型中的一种。
Riak 并不是惟一的一种 NoSQL 数据存储。另外两种较流行的数据存储是 MongoDB 和 Cassandra。尽管在许多方面十分相似,但是它们之间也存在明显的不同。例如,Riak 是一种分布式系统,而 MongoDB 是一种单独的系统数据库,也就是说,Riak 没有主节点的概念,因此在处理故障方面有更好的弹性。尽管 Cassandra 同样是基于 Amazon 的 Dynamo 描述,但是它在组织数据方面摒弃了向量时钟和相容散列等特性。Riak 的数据模型更加灵活。在 Riak 中,在第一次访问 bucket 时会动态创建这些 bucket;Cassandra 的数据模型是在 XML 文件中定义的,因此在修改它们过后需要重启整个群集。
Riak 的另一个优势是它是用 Erlang 编写的。而 MongoDB 和 Cassandra 是用通用语言(分别为 C++和 Java)编写,因此 Erlang 从一开始就支持分布式、容错应用程序,所以更加适用于开发 NoSQL 数据存储等应用程序,这些应用程序与使用 Erlang 编写的应用程序有一些共同的特征。
Map/Reduce 作业只能使用 Erlang 或 JavaScript 编写。对于本文呢,我们选择使用 JavaScript 编写 map 和 reduce 函数,但是也可以用 Erlang 编写它们。虽然 Erlang 代码的执行速度可能稍快一些,然而我们选择 JavaScript 代码的理由是它的受众更广。参阅 参考资料 中的链接,详细了解 Erlang。
开始
如果您希望尝试本文中的一些示例,则需要在您的系统中安装 Riak(参阅 参考资料)和 Erlang。
您还需要构建一个包含三个节点的群集并在您的本地机器上运行它。Riak 中保存的所有数据都被复制到群集的大量节点中。数据所在的 bucket 的一个属性 (n_val) 决定了将要复制的节点的数量。该属性的默认值为 3,因此,要完成本示例,我们需要创建一个至少包含三个节点的群集(之后您可以创建任意数量的节点)。
下载了源代码后,您需要进行构建。基本步骤如下:
解压缩源代码:$ tar xzvf riak-1.0.1.tar.gz
修改目录:$ cd riak-1.0.1
构建:$ make all rel
这将构建 Riak (./rel/riak)。要在本地运行多个节点,则需要生成 ./rel/riak 的副本,对每个额外的节点使用一个副本。将 ./rel/riak 复制到 ./rel/riak2、./rel/riak3 等地方,然后对每个副本执行下面的修改:
在 riakN/etc/app.config 中,修改下面的值:http{} 部分中指定的端口,handoff_port 和 pb_port,将它们修改为惟一值
打开 riakN/etc/vm.args 并修改名称,同样是修改为惟一值,例如 -name riak2@127.0.0.1
现在依次启动每个节点,如 清单 1 所示。
清单 1. 清单 1. 启动每个节点
$ cd rel $ ./riak/bin/riak start $ ./riak2/bin/riak start $ ./riak3/bin/riak start
最后,将节点连接起来形成群集,如 清单 2 所示。
清单 2. 清单 2. 形成群集
$ ./riak2/bin/riak-admin join riak@127.0.0.1 $ ./riak3/bin/riak-admin join riak@127.0.0.1
您现在应该创建了一个在本地运行的 3 节点群集。要进行测试,运行如下命令: $ ./riak/bin/riak-admin status | grep ring_members。
您应当看到,每个节点都是刚刚创建的群集的一部分,例如 ring_members : ['riak2@127.0.0.1','riak3@127.0.0.1','riak@127.0.0.1']。
Riak API
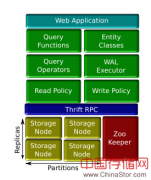
目前有三种方式可以访问 Riak:HTTP API(RESTful 界面)、Protocol Buffers 和一个原生 Erlang 界面。提供多个界面使您能够选择如何集成应用程序。如果您使用 Erlang 编写应用程序,那么应当使用原生的 Erlang 界面,这样就可以将二者紧密地集成在一起。其他一些因素也会影响界面的选择,比如性能。例如,使用 Protocol Buffers 界面的客户端的性能要比使用 HTTP API 的客户端性能更高一些;从性能方面讲,数据通信量变小,解析所有这些 HTTP 标头的开销相对更高。然而,使用 HTTP API 的优点是,如今的大部分开发人员(特别是 Web 开发人员)非常熟悉 RESTful 界面,再加上大多数编程语言都有内置的原语,支持通过 HTTP 请求资源,例如,打开一个 URL,因此不需要额外的软件。在本文中,我们将重点介绍 HTTP API。
所有示例都将使用 curl 通过 HTTP 界面与 Riak 交互。这样做是为了更好地理解底层的 API。许多语言都提供了大量客户端库,在开发使用 Riak 作为数据存储的应用程序时,应当考虑使用这些客户端库。客户端库提供了与 Riak 连接的 API,可以轻松地与应用程序集成;您不必亲自编写代码来处理在使用 curl 时出现的响应。
API 支持常见的 HTTP 方法:GET、PUT、POST、DELETE,它们将分别用于检索、更新、创建和删除对象。我们稍后将依次介绍每一种方法。
存储对象
您可以将 Riak 看成是创建键(字符串)与值(对象)的分布式映射。Riak 将值保存在 bucket 中。在保存对象之前,不需要显式地创建 bucket;如果将对象保存到一个不存在的 bucket 中,则会自动创建该 bucket。
Bucket 在 Riak 中是一个虚拟概念,主要是为了对相关对象分组而存在。bucket 还具有其他一些属性,这些属性的值定义了 Riak 对存储在其中的对象的处理。下面是 bucket 属性的一些示例:
- n_val:对象在群集内进行复制的次数
- allow_mult:是否允许并发更新
您可以通过对 bucket 发出 GET 请求查看 bucket 的属性(及其当前值)。
要存储对象,我们将对 清单 3 所示的其中一个 URL 执行 HTTP POST。
清单 3. 清单 3. 存储对象
POST -> /riak/<bucket> (1) POST -> /riak/<bucket>/<key> (2)
键可以由 Riak (1)自动分配,或由用户 (2) 定义。
当使用用户定义的键存储对象时,也可以向 (2) 执行一个 HTTP PUT 操作来创建对象。
Riak 的最新版本还支持以下 URL 格式:/buckets/<bucket>/keys/<key>,但是在本文中,我们将使用更旧的格式来维持与早期 Riak 版本的向后兼容性。
如果没有指定键,Riak 会自动为对象分配一个键。例如,我们将在 bucket “foo” 中存储一个明文对象,并且不会显式指定键(参见 清单 4)。
清单 4. 清单 4. 在不显式指定键的情况下存储一个明文对象
$ curl -i -H "Content-Type: plain/text" -d "Some text" http://localhost:8098/riak/foo/ HTTP/1.1 201 Created Vary: Accept-Encoding Location: /riak/foo/3vbskqUuCdtLZjX5hx2JHKD2FTK Content-Type: plain/text Content-Length: ...
通过检查 Location 标头,您可以看到 Riak 分配给对象的键。这样做不容易记忆,因此另一种选择是让用户提供键。让我们创建一个艺术家 bucket,并添加一个叫做 Bruce 的艺术家(参见 清单 5)。
清单 5. 清单 5. 创建一个艺术家 bucket 并添加一个艺术家
$ curl -i -d '{"name":"Bruce"}' -H "Content-Type: application/json"
http://localhost:8098/riak/artists/Bruce
HTTP/1.1 204 No Content
Vary: Accept-Encoding
Content-Type: application/json
Content-Length: ...
如果使用我们指定的键成功存储了对象,我们将从服务器得到一个 204 No Content 响应。
在本例中,我们将对象的值保存为 JSON,但是它既可以是明文格式,也可以是其他格式。在存储对象时,需要注意正确设置 Content-Type 标头。例如,如果希望存储一个 JPEG 图像,那么您必须将内容类型设置为 image/jpeg。
检索对象
要检索已存储的对象,使用您希望检索的对象的键对 bucket 运行 GET 方法。如果对象存在,则会在响应的正文中返回对象,否则服务器会返回 404 Object Not Found 响应(参见 清单 6)。
清单 6. 清单 6. 在 bucket 上执行一个 GET 方法
$ curl http://localhost:8098/riak/artists/Bruce
HTTP/1.1 200 OK
...
{ "name" : "Bruce" }
更新对象
在更新对象时,和存储对象一样,需要用到 Content-Type 标头。例如,让我们来添加 Bruce 的别名,如 清单 7 所示。
清单 7. 清单 7. 添加 Bruce 的别名
$ curl -i -X PUT -d '{"name":"Bruce", "nickname":"The Boss"}'
-H "Content-Type: application/json" http://localhost:8098/riak/artists/Bruce
如前所述,Riak 自动创建了 bucket。这些 bucket 拥有一些属性,其中一个属性为 allow_mult,用于确定是否允许执行并发写操作。默认情况下,该属性被设置为 false;但是,如果允许进行并发更新,则需要向每个更新发送 X-Riak-Vclock 标头。应该将该标头的值设置为与客户端最后一次读取对象时看到的值相同。
Riak 使用向量时钟 (vector clock) 判断修改对象的原因。向量时钟的工作原理超出了本文的讨论范围,但是,在允许执行并发写操作时,可能会出现冲突,这时需要使用应用程序来解决这些冲突(参阅 参考资料)。
删除对象
删除对象的操作使用了一个与前面的命令类似的模式,我们只需要对希望删除的对象所对应的 URL 执行一个 HTTP DELETE 方法: $ curl -i -X DELETE http://localhost:8098/riak/artists/Bruce。
如果成功删除对象,我们会从服务器获得一个 204 No Content 响应;如果试图删除的对象不存在,那么服务器会返回一个 404 Object Not Found 响应。
原文地址:http://www.ibm.com/developerworks/cn/opensource/os-riak1/
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。