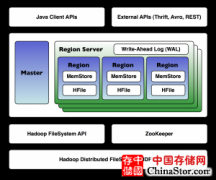
使用HBase的Java API来建表,插入数据以及按照行主键查询数据。我们也会建立一个限制列范围的基本表查询,以及使用过滤器进行分页查询。
导航:使用HBase处理海量数据系列文章共5章:1、HBase的概要介绍;2、初步了解HBase交互;3、HBASE架构了解;4、HBase中Java API使用;5、数据建模。
第三篇中,我们从整体了解了HBase的架构。本文中,我们使用HBase的Java API来建表,插入数据以及按照行主键查询数据。我们也会建立一个限制列范围的基本表查询,以及使用过滤器进行分页查询。
之前学习了HBase的整体架构,现在了解一下我们的应用如何通过Java API与HBase进行交互。如同之前提到的,你也同样可以通过其他的RPC(Remote Procedure Call)技术手段与HBase交互,比如Apache Thrift通过REST网关的方式,但我们主要使用Java API的方式。API提供了DDL(数据定义语言)和DML(数据操作语言)你会发现和关系型数据库SQL的语言很相似。假设我们要存储用户信息,我们先开始建立一张新表。下列代码展示如何使用HBaseAdmin类。
|
1
2
3
4
5
6
7
|
Configuration conf = HBaseConfiguration.create();HBaseAdmin admin = new HBaseAdmin(conf);HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("people"));tableDescriptor.addFamily(new HColumnDescriptor("personal"));tableDescriptor.addFamily(new HColumnDescriptor("contactinfo"));tableDescriptor.addFamily(new HColumnDescriptor("creditcard"));admin.createTable(tableDescriptor); |
用户表定义包含三个列簇:个人信息、联系信息以及信用卡。你需要用HTableDescriptor构建一张表,并且使用HColumnDescriptor添加一个或多个列簇。然后调用createTable方法建表。完成之后来添加一些数据。下面的代码展示了如何使用Put类插入John Doe的数据,指定名称和电子邮件指定(为了简单期间,这里忽略了通常应该有的错误处理)
|
1
2
3
4
5
6
7
8
9
10
|
Configuration conf = HBaseConfiguration.create();HTable table = new HTable(conf, "people");Put put = new Put(Bytes.toBytes("doe-john-m-12345"));put.add(Bytes.toBytes("personal"), Bytes.toBytes("givenName"), Bytes.toBytes("John"));put.add(Bytes.toBytes("personal"), Bytes.toBytes("mi"), Bytes.toBytes("M"));put.add(Bytes.toBytes("personal"), Bytes.toBytes("surame"), Bytes.toBytes("Doe"));put.add(Bytes.toBytes("contactinfo"), Bytes.toBytes("email"), Bytes.toBytes("john.m.doe@gmail.com"));table.put(put);table.flushCommits();table.close(); |
上面的代码中示例是Put类提供了唯一行主键作为构造方法参数。接下来我们会添加值,必须包括列簇、列标识符、二进制数组形式的值。或许你会注意到,HBase API的常用工具类中的Bytes类是经常用到的,它提供了一些方法能够在原始类型、字符串与二进制数组间转换。(添加一个toBytes()静态引用方法能够节省大堆代码)接下来我们将数据存入表中,刷新提交确认本地缓存的改变能够生效,最终关闭表。更新数据也和之前展示的代码方式相同。与关系型数据库不同,HBase即使只有一列改变也必须更新整行数据。假如你只需要更新一列,只需要在Put类和HBase中指定需要更新的列。也会有确认并更新的动作,本质上就是一系列并发操作,只是在用户确认待替换的值之后才进行更新动作。
如下面的代码所示,使用Get类来查询我们刚刚创建完成的数据。(从这里开始,会忽略一些代码如构建配置,实例化HTable、提交及关闭)
|
1
2
3
4
|
Get get = new Get(Bytes.toBytes("doe-john-m-12345"));get.addFamily(Bytes.toBytes("personal"));get.setMaxVersions(3);Result result = table.get(get); |
上面的代码中实例化了Get类,并且提供了待查询的行主键。接下来我们通过 addFamily 方法告知HBase:我们只需要从个人信息列簇中获取数据。这样能够减少HBase在读取数据时与磁盘的交互。我们还指定了结果中每列最多保存三个版本,这样就能列出每列的历史数据。最终会返回一个结果实例,包含所有可以查看的返回值列。
很多情况下你需要查询多行数据,HBase使用扫描行来实现。正如在第二篇在HBase的shell工具中执行scan,下面主要讨论Scan类。Scan类支持多种条件选项,比如待查询的行主键范围、需要包含的列和列簇、以及需要展示的最大数据版本。你也可以添加一个过滤器,通过自定义过滤逻辑限制需要返回哪些行和列。过滤器的常用场景就是分页,例如我们可能想要获取所有的姓Smith的人,每次一页25人。下面的代码展示了如何使用基本的scan方法。
|
1
2
3
4
5
6
7
8
|
Scan scan = new Scan(Bytes.toBytes("smith-"));scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("givenName"));scan.addColumn(Bytes.toBytes("contactinfo"), Bytes.toBytes("email"));scan.setFilter(new PageFilter(25));ResultScanner scanner = table.getScanner(scan);for (Result result : scanner) { // ...} |
上面的代码中,我们新建了一个Scan类,查询以 smith- 开头的行主键,使用 addColumn 来限制返回的列(这样就能够减少HBase与磁盘磁盘传输)为 personal:givenName 和 contactinfo:email两列。scan中的PageFilter用于限制扫描的行数为25.(也可以考虑使用在Scan构造函数中指定结束行主键的分页过滤器)。我们使用结果扫描类来查看刚才的结果,循环并执行业务动作。在HBase中,唯一查询多行数据的方式就是根据排序的行主键扫描,因此如何设计行主键就显得很重要。稍候会对此再进行讨论。
你也可以使用Delete类删除HBase中的数据,和Put类相似删除了一行中的所有列(意味着完全删除了行),删除了列簇、列、等类似的组合。
处理连接
上面的示例对如何处理连接以及远程调用(RPC)没有太多关注。HBase提供了HConnection类用于提供类似于连接池的功能共用连接,例如你使用 getTable() 方法来获得一个HTable实例的引用。同样,也有一个HConnectionManager类提供HConnection实例。类似Web应用中避免网络频繁交换,可以有效地管理RPC的数量。在使用HBase时,返回的海量数据这类的问题很重要的。编写HBase应用时要考虑类似的问题。
总结
本文中,我们用HBase的Java API来建立一个用户表,插入新用户,然后查找新插入的用户信息。还使用了Scan类在用户表中查找姓 “Smith” 的用户,并且展示如何限制数据查询。最终通过过滤器来限制返回结果的数量。
下一篇中,我们将学习如何在HBase中面对无SQL特性和关系的情况下,建立模型结构。
原文链接: dzone 翻译: ImportNew.com - 陈 晨
译文链接: http://www.importnew.com/8932.html
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。