ZFS(Zettabyte File System)是由SUN公司设计的一种基于Solaris的文件系统,相对于传统的EXT、XFS、JFS、ReiserFS或NTFS,ZFS的一个重要侧重点就是突出了对数据完整性的保护。
什么是 ZFS?
ZFS(Zettabyte File System)是由SUN公司的Jeff Bonwick领导设计的一种基于Solaris的文件系统,最初发布于20014年9月14日。 SUN被Oracle收购后,现在称为Oracle Solaris ZFS。
ZFS全称是 Zettabyte File System,单个ZFS文件系统最多支持 256 quadrillion zettabytes (ZB), 1ZB等于2的70次方字节。相对于传统的EXT、XFS、JFS、ReiserFS或NTFS,ZFS的一个重要侧重点就是突出了对数据完整性的保护。
ZFS 文件系统是一种革新性的新文件系统,可从根本上改变文件系统的管理方式,并具有目前面市的其他任何文件系统所没有的功能和优点。ZFS 强健可靠、可伸缩、易于管理。
因为其先进性,ZFS被称为最后的操作系统,21世纪最好的操作系统,也曾经被苹果用于Mac OSX 10.5操作系统中,但是当Mac OSX10.6雪豹发布时,大家发现苹果完全弃用了ZFS。
原因可能是,当Oracle收购SUN时,Oracle自己已经有了开源文件系统BTRFS,外界认为它无力分身继续ZFS的开发;另一方面,Netapp称ZFS文件系统侵犯其WAFL专利技术,综合这些,苹果最终停止支持ZFS文件系统。

ZFS曾获2008最佳文件系统奖
ZFS 池存储
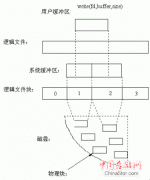
ZFS 使用存储池的概念来管理物理存储。以前,文件系统是在单个物理设备的基础上构造的。为了利用多个设备和提供数据冗余性,引入了卷管理器的概念来提供单个设备的表示,以便无需修改文件系统即可利用多个设备。此设计增加了更多复杂性,并最终阻碍了特定文件系统的继续发展,因为这类文件系统无法控制数据在虚拟卷上的物理放置。
ZFS 可完全避免使用卷管理。ZFS 将设备聚集到存储池中,而不是强制要求创建虚拟卷。存储池说明了存储的物理特征(设备布局、数据冗余等),并充当可以从其创建文件系统的任意数据存储库。文件系统不再仅限于单个设备,从而可与池中的所有文件系统共享磁盘空间。您不再需要预先确定文件系统的大小,因为文件系统会在分配给存储池的磁盘空间内自动增长。添加新存储器后,无需执行其他操作,池中的所有文件系统即可立即使用所增加的磁盘空间。在许多方面,存储池与虚拟内存系统相似:将一个内存 DIMM 加入系统时,操作系统并不强迫您运行命令来配置内存并将其指定给个别进程。系统中的所有进程都会自动使用所增加的内存。
事务性语义
ZFS 是事务性文件系统,这意味着文件系统状态在磁盘上始终是一致的。传统文件系统可就地覆写数据,这意味着如果系统断电(例如,在分配数据块到将其链接到目录中的时间段内断电),则会使文件系统处于不一致状态。以前,此问题是通过使用 fsck 命令解决的。此命令负责检查并验证文件系统状态,并尝试在操作过程中修复任何不一致性。这种文件系统不一致问题曾给管理员造成巨大困扰,fsck 命令并不保证能够解决所有可能的问题。最近,文件系统引入了日志记录的概念。日志记录过程在单独的日志中记录操作,在系统发生崩溃时,可以安全地重放该日志。由于数据需要写入两次,因此该过程会引入不必要的开销,而且通常会导致一组新问题,例如在无法正确地重放日志时。
对于事务性文件系统,数据是使用写复制语义管理的。数据永远不会被覆写,并且任何操作序列会全部被提交或全部被忽略。因此,文件系统绝对不会因意外断电或系统崩溃而被损坏。尽管最近写入的数据片段可能丢失,但是文件系统本身将始终是一致的。此外,只有在写入同步数据(使用 O_DSYNC 标志写入)后才返回,因此同步数据决不会丢失。
校验和与自我修复数据
对于 ZFS,所有数据和元数据都通过用户可选择的校验和算法进行验证。提供校验和验证的传统文件系统出于卷管理层和传统文件系统设计的必要,会逐块执行此操作。在传统设计中,某些故障可能导致数据不正确但没有校验和错误,如向错误位置写入完整的块等。ZFS 校验和的存储方式可确保检测到这些故障并可以正常地从其中进行恢复。所有校验和验证与数据恢复都是在文件系统层 执行的,并且对应用程序是透明的。
此外,ZFS 还会提供自我修复数据。ZFS 支持存储池具有各种级别的数据冗余性。检测到坏的数据块时,ZFS 会从另一个冗余副本中提取正确的数据,而且会用正确的数据替换错误的数据。
独一无二的可伸缩性
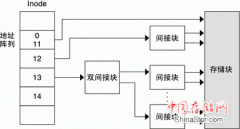
ZFS 文件系统的一个关键设计要素是可伸缩性。该文件系统本身是 128 位的,所允许的存储空间是 256 quadrillion zettabyte (256x1015 ZB)。所有元数据都是动态分配的,因此在首次创建时无需预先分配 inode,否则就会限制文件系统的可伸缩性。所有算法在编写时都考虑到了可伸缩性。目录最多可以包含 248(256 万亿)项,并且对于文件系统数或文件系统中可以包含的文件数不存在限制。
ZFS 快照
快照是文件系统或卷的只读副本。可以快速而轻松地创建快照。最初,快照不会占用池中的任何附加磁盘空间。
活动数据集中的数据更改时,快照通过继续引用旧数据来占用磁盘空间。因此,快照可防止将数据释放回池中。
简化的管理
最重要的是,ZFS 提供了一种极度简化的管理模型。通过使用分层文件系统布局、属性继承以及自动管理挂载点和 NFS 共享语义,ZFS 可轻松创建和管理文件系统,而无需使用多个命令或编辑配置文件。可以轻松设置配额或预留空间,启用或禁用压缩,或者通过单个命令管理许多文件系统的挂载点。您就可以检查或替换设备,而无需学习另外的一套卷管理命令。您可以发送和接收文件系统快照流
ZFS 通过分层结构管理文件系统,该分层结构允许对属性(如配额、预留空间、压缩和挂载点)进行这一简化管理。在此模型中,文件系统是中央控制点。文件系统本身的开销非常小(相当于创建一个新目录),因此鼓励您为每个用户、项目、工作区等创建一个文件系统。通过此设计,可定义细分的管理点。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。