作为电脑中必不可少的三大件之一(其余的两个是主板与CPU), 内存 是决定系统性能的关键设备之一,它就像一个临时的仓库,负责数据的中转、暂存 不过,虽然内存对系统性能的至关重要,但长期以来,DIYer并不重视内存,只是将它看作是一种买主板和CPU时顺带
作为电脑中必不可少的三大件之一(其余的两个是主板与CPU),内存是决定系统性能的关键设备之一,它就像一个临时的仓库,负责数据的中转、暂存
不过,虽然内存对系统性能的至关重要,但长期以来,DIYer并不重视内存,只是将它看作是一种买主板和CPU时顺带买的“附件”,那时最多也就注意一下内存的速度。这种现象截止于1998年440BX主板上市后,PC66/100的内存标准开始进入普通DIYer的视野,因为这与选购有着直接的联系。一时间,有关内存时序参数的介绍文章大量出现(其中最为著名的恐怕就是CL参数)。自那以后,DIYer才发现,原来内存也有这么多的学问。接下来,始于2000年底/2001年初的VIA芯片组4路交错(4-Way Interleave)内存控制和部分芯片组有关内存容量限制的研究,则是深入了解内存的一个新开端。本刊在2001年第2期上也进行了VIA内存交错控制与内存与模组结构的详细介绍,并最终率先正确地解释了这一类型交错(内存交错有多种类型)的原理与容量限制的原因。从那时起,很多关于内存方面的深入性文章接踵而至,如果说那时因此而掀起了一股内存热并不夸张。大量的内存文章让更多的用户了解了内存,以及更深一层的知识,这对于DIY当然是一件好事情。然而,令人遗憾的是这些所谓的内存高深技术文章有不少都是错的(包括后来的DDR与RDRAM内存的介绍),有的甚至是很低级的错误。在这近两年的时间里,国内媒体上优秀的内存技术文章可谓是寥若晨星,有些媒体还编译国外DIY网站的大篇内存文章,但可惜的是,外国网站也不见得都是对的(这一点,似乎国内很多作者与媒体似乎都忽视了)。就这样,虽然打开了一个新的知识领域,可“普及”的效果并不那么好,很多媒体的铁杆读者高兴地被带入内存深层世界,但也因此被引向了新的误区。
不过,从这期间(2001年初至今)各媒体读者对这类文章的反映来看,喜欢内存技术的玩家大有人在且越来越多,这是各媒体“培养”的成果。这些用户已经不满足如何正确的使用内存,他们更渴望深入的了解这方面原来非常贫乏的知识,这些知识可能暂时不会对他们在使用内存过程中有什么帮助,但会大大满足他们的求知欲。在2001年初,我们揭开VIA芯片组4路交错内存控制和部分芯片组有关内存容量限制之迷时,还是主要围绕着内存使用的相关话题来展开,而且在这期间有关内存技术的话题,《电脑高手》也都是一笔带过。但在今天,在很多人希望了解内存技术而众多媒体的文章又“力不从心”时,我们觉得有必要再次站出来以正视听,也就是说,我们这次的专题不再以内存使用为中心,更多的是纯技术性介绍,并对目前现存的主要内存技术误区进行重点纠正。
在最后要强调的是,本专题以技术为主,由于篇幅的原因,不可能从太浅的方面入手,所以仍需要有一定的技术基础作保证,而对内存感兴趣的读者则绝不容错过,这也许是您最好的纠正错误认识的机会!
在本专题里,当讲完内存的基本操作之后,我们会给大家讲一个仓库的故事,从中相信您会更了解内存这个仓库是怎么工作的,希望您能喜欢。
SDRAM与内存基础概念(一)
虽然有关内存结构与时序的基础概念,在本刊2001年第2期的专题中就已有阐述,但在这里为了保证专题的可读性,我们需要再次加强这方面的系统认识。正确并深刻理解内存的基础概念,是阅读本专题的第一条件。因为即使是RDRAM,在很多方面也是与SDRAM相似的,而至于DDR与DDR-Ⅱ、QBM等形式的内存更是与SDRAM有着紧密的联系。
一、 SDRAM内存模组与基本结构
我们平时看到的SDRAM都是以模组形式出现,为什么要做成这种形式呢?这首先要接触到两个概念:物理Bank与芯片位宽。

PC133时代的168pin SDRAM DIMM
1、 物理Bank
传统内存系统为了保证CPU的正常工作,必须一次传输完CPU在一个传输周期内所需要的数据。而CPU在一个传输周期能接受的数据容量就是CPU数据总线的位宽,单位是bit(位)。当时控制内存与CPU之间数据交换的北桥芯片也因此将内存总线的数据位宽等同于CPU数据总线的位宽,而这个位宽就称之为物理Bank(Physical Bank,下文简称P-Bank)的位宽。所以,那时的内存必须要组织成P-Bank来与CPU打交道。资格稍老的玩家应该还记得Pentium刚上市时,需要两条72pin的SIMM才能启动,因为一条72pin -SIMM只能提供32bit的位宽,不能满足Pentium的64bit数据总线的需要。直到168pin-SDRAM DIMM上市后,才可以使用一条内存开机。下面将通过芯片位宽的讲述来进一步解释P-Bank的概念。
不过要强调一点,P-Bank是SDRAM及以前传统内存家族的特有概念,在RDRAM中将以通道(Channel)取代,而对于像Intel E7500那样的并发式多通道DDR系统,传统的P-Bank概念也不适用。

2、 芯片位宽
上文已经讲到SDRAM内存系统必须要组成一个P-Bank的位宽,才能使CPU正常工作,那么这个P-Bank位宽怎么得到呢?这就涉及到了内存芯片的结构。
每个内存芯片也有自己的位宽,即每个传输周期能提供的数据量。理论上,完全可以做出一个位宽为64bit的芯片来满足P-Bank的需要,但这对技术的要求很高,在成本和实用性方面也都处于劣势。所以芯片的位宽一般都较小。台式机市场所用的SDRAM芯片位宽最高也就是16bit,常见的则是8bit。这样,为了组成P-Bank所需的位宽,就需要多颗芯片并联工作。对于16bit芯片,需要4颗(4×16bit=64bit)。对于8bit芯片,则就需要8颗了。

以上就是芯片位宽、芯片数量与P-Bank的关系。P-Bank其实就是一组内存芯片的集合,这个集合的容量不限,但这个集合的总位宽必须与CPU数据位宽相符。随着计算机应用的发展,一个系统只有一个P-Bank已经不能满足容量的需要。所以,芯片组开始可以支持多个P-Bank,一次选择一个P-Bank工作,这就有了芯片组支持多少(物理)Bank的说法。而在Intel的定义中,则称P-Bank为行(Row),比如845G芯片组支持4个行,也就是说它支持4个P-Bank。另外,在一些文档中,也把P-Bank称为Rank(列)。
回到开头的话题,DIMM是SDRAM集合形式的最终体现,每个DIMM至少包含一个P-Bank的芯片集合。在目前的DIMM标准中,每个模组最多可以包含两个P-Bank的内存芯片集合,虽然理论上完全可以在一个DIMM上支持多个P-Bank,比如SDRAM DIMM就有4个芯片选择信号(Chip Select,简称片选或CS),理论上可以控制4个P-Bank的芯片集合。只是由于某种原因而没有这么去做。比如设计难度、制造成本、芯片组的配合等。至于DIMM的面数与P-Bank数量的关系,在2001年2月的专题中已经明确了,面数≠P-Bank数,只有在知道芯片位宽的情况下,才能确定P-Bank的数量,大度256MB内存就是明显一例,而这种情况在Registered模组中非常普遍。有关内存模组的设计,将在后面的相关章节中继续探讨。 #p#一、 SDRAM内存模组与基本结构#e#
SDRAM与内存基础概念(二)
二、 SDRAM内存芯片的内部结构
1、逻辑Bank与芯片位宽
讲完SDRAM的外在形式,就该深入了解SDRAM的内部结构了。这里主要的概念就是逻辑Bank。简单地说,SDRAM的内部是一个存储阵列。因为如果是管道式存储(就如排队买票),就很难做到随机访问了。
阵列就如同表格一样,将数据“填”进去,你可以它想象成一张表格。和表格的检索原理一样,先指定一个行(Row),再指定一个列(Column),我们就可以准确地找到所需要的单元格,这就是内存芯片寻址的基本原理。对于内存,这个单元格可称为存储单元,那么这个表格(存储阵列)叫什么呢?它就是逻辑Bank(Logical Bank,下文简称L-Bank)。
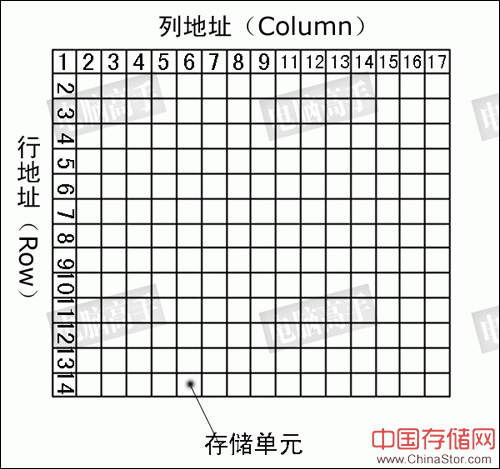
L-Bank存储阵列示意图
由于技术、成本等原因,不可能只做一个全容量的L-Bank,而且最重要的是,由于SDRAM的工作原理限制,单一的L-Bank将会造成非常严重的寻址冲突,大幅降低内存效率(在后文中将详细讲述)。所以人们在SDRAM内部分割成多个L-Bank,较早以前是两个,目前基本都是4个,这也是SDRAM规范中的最高L-Bank数量。到了RDRAM则最多达到了32个,在最新DDR-Ⅱ的标准中,L-Bank的数量也提高到了8个。
这样,在进行寻址时就要先确定是哪个L-Bank,然后再在这个选定的L-Bank中选择相应的行与列进行寻址。可见对内存的访问,一次只能是一个L-Bank工作,而每次与北桥交换的数据就是L-Bank存储阵列中一个“存储单元”的容量。在某些厂商的表述中,将L-Bank中的存储单元称为Word(此处代表位的集合而不是字节的集合)。
从前文可知,SDRAM内存芯片一次传输率的数据量就是芯片位宽,那么这个存储单元的容量就是芯片的位宽(也是L-Bank的位宽),但要注意,这种关系也仅对SDRAM有效,原因将在下文中说明。
2、内存芯片的容量
现在我们应该清楚内存芯片的基本组织结构了。那么内存的容量怎么计算呢?显然,内存芯片的容量就是所有L-Bank中的存储单元的容量总合。计算有多少个存储单元和计算表格中的单元数量的方法一样:
存储单元数量=行数×列数(得到一个L-Bank的存储单元数量)×L-Bank的数量
在很多内存产品介绍文档中,都会用M×W的方式来表示芯片的容量(或者说是芯片的规格/组织结构)。M是该芯片中存储单元的总数,单位是兆(英文简写M,精确值是1048576,而不是1000000),W代表每个存储单元的容量,也就是SDRAM芯片的位宽(Width),单位是bit。计算出来的芯片容量也是以bit为单位,但用户可以采用除以8的方法换算为字节(Byte)。比如8M×8,这是一个8bit位宽芯片,有8M个存储单元,总容量是64Mbit(8MB)。
不过,M×W是最简单的表示方法。下图则是某公司对自己内存芯片的容量表示方法,这可以说是最正规的形式之一。

业界正规的内存芯片容量表示方法
我们可以计算一下,结果可以发现这三个规格的容量都是128Mbits,只是由于位宽的变化引起了存储单元的数量变化。从这个例子就也可以看出,在相同的总容量下,位宽可以采用多种不同的设计。
3、与芯片位宽相关的DIMM设计
为什么在相同的总容量下,位宽会有多种不同的设计呢?这主要是为了满足不同领域的需要。现在大家已经知道P-Bank的位宽是固定的,也就是说当芯片位宽确定下来后,一个P-Bank中芯片的个数也就自然确定了,而前文讲过P-Bank对芯片集合的位宽有要求,对芯片集合的容量则没有任何限制。高位宽的芯片可以让DIMM的设计简单一些(因为所用的芯片少),但在芯片容量相同时,这种DIMM的容量就肯定比不上采用低位宽芯片的模组,因为后者在一个P-Bank中可以容纳更多的芯片。比如上文中那个内存芯片容量标识图,容量都是128Mbit,合16MB。如果DIMM采用双P-Bank+16bit芯片设计,那么只能容纳8颗芯片,计128MB。但如果采用4bit位宽芯片,则可容纳32颗芯片,计512MB。DIMM容量前后相差出4倍,可见芯片位宽对DIMM设计的重要性。因此,8bit位宽芯片是桌面台式机上容量与成本之间平衡性较好的选择,所以在市场上也最为普及,而高于16bit位宽的芯片一般用在需要更大位宽的场合,如显卡等,至于4bit位宽芯片很明显非常适用于大容量内存应用领域,基本不会在标准的Unbuffered 模组设计中出现。 #p#二、 SDRAM内存芯片的内部结构#e#
SDRAM与内存基础概念(三)
三、 SDRAM的引脚与封装
内存芯片要想工作,必须要与内存控制器有所联系,同时对于一个电气元件,电源供应也是必不可少的,而且数据的传输要有一个时钟作为触发参考。因此,SDRAM在封装时就要留出相应的引脚以供使用。电源与时钟的引脚就不必多说了,现在我们可以想象一下,至少应该有哪些控制引脚呢?
我们从内存寻址的步骤缕下来就基本明白了,从中我们也就能了解内存工作的大体情况。这里需要说明的是,与DIMM一样,SDRAM有着自己的业界设计规范,在一个容量标准下,SDRAM的引脚/信号标准不能只考虑一种位宽的设计,而是要顾及多种位宽,然后尽量给出一个通用的标准,小位宽的芯片也许会空出一些引脚,但高位宽的芯片可能就全部用上了。不过容量不同时,设计标准也会有所不同,一般的容量越小的芯片所需要的引脚也就越小。
1、 首先,我们知道内存控制器要先确定一个P-Bank的芯片集合,然后才对这集合中的芯片进行寻址操作。因此要有一个片选的信号,它一次选择一个P-Bank的芯片集(根据位宽的不同,数量也不同)。被选中的芯片将同时接收或读取数据,所以要有一个片选信号。
2、 接下来是对所有被选中的芯片进行统一的L-Bank的寻址,目前SDRAM中L-Bank的数量最高为4个,所以需要两个L-Bank地址信号(22=4)。
3、 最后就是对被选中的芯片进行统一的行/列(存储单元)寻址。地址线数量要根据芯片的组织结构分别设计了。但在相同容量下,行数不变,只有列数会根据位宽的而变化,位宽越大,列数越少,因为所需的存储单元减少了。
4、 找到了存储单元后,被选中的芯片就要进行统一的数据传输,那么肯定要有与位宽相同数量的数据I/O通道才行,所以肯定要有相应数量的数据线引脚。
现在我们就基本知道了内存芯片的一些信号引脚,下图就是一个简单的SDRAM示意图,大家可以详细看看。
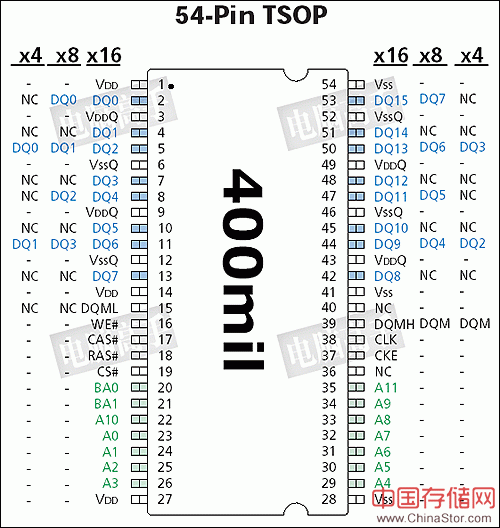
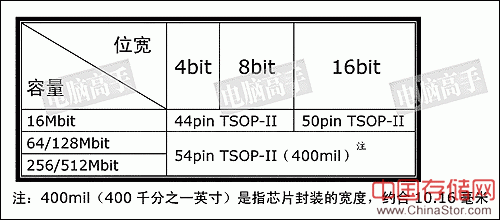
图注:128Mbit芯片不同位宽的引脚图(NC代表未使用,-表示与内侧位宽设计相同)
根据SDRAM的官方规范,台式机上所用的SDRAM在不同容量下的各种位宽封装标准如下:
#p#四、SDRAM的内部基本操作与工作时序#e#
SDRAM与内存基础概念(四)
四、SDRAM的内部基本操作与工作时序
上文我们已经了解了SDRAM所用到的基本信号线路,下面就看看它们在SDRAM芯片内部是怎么“布置”的,并从这里开始深入了解内存的基本操作与过程,在这一节中我们将接触到有天书之称的时序图,但不要害怕,根据文中的指导慢慢理解,您肯定可以看懂它。首先,我们先认识一下SDRAM的内部结构,然后再开始具体的讲述。
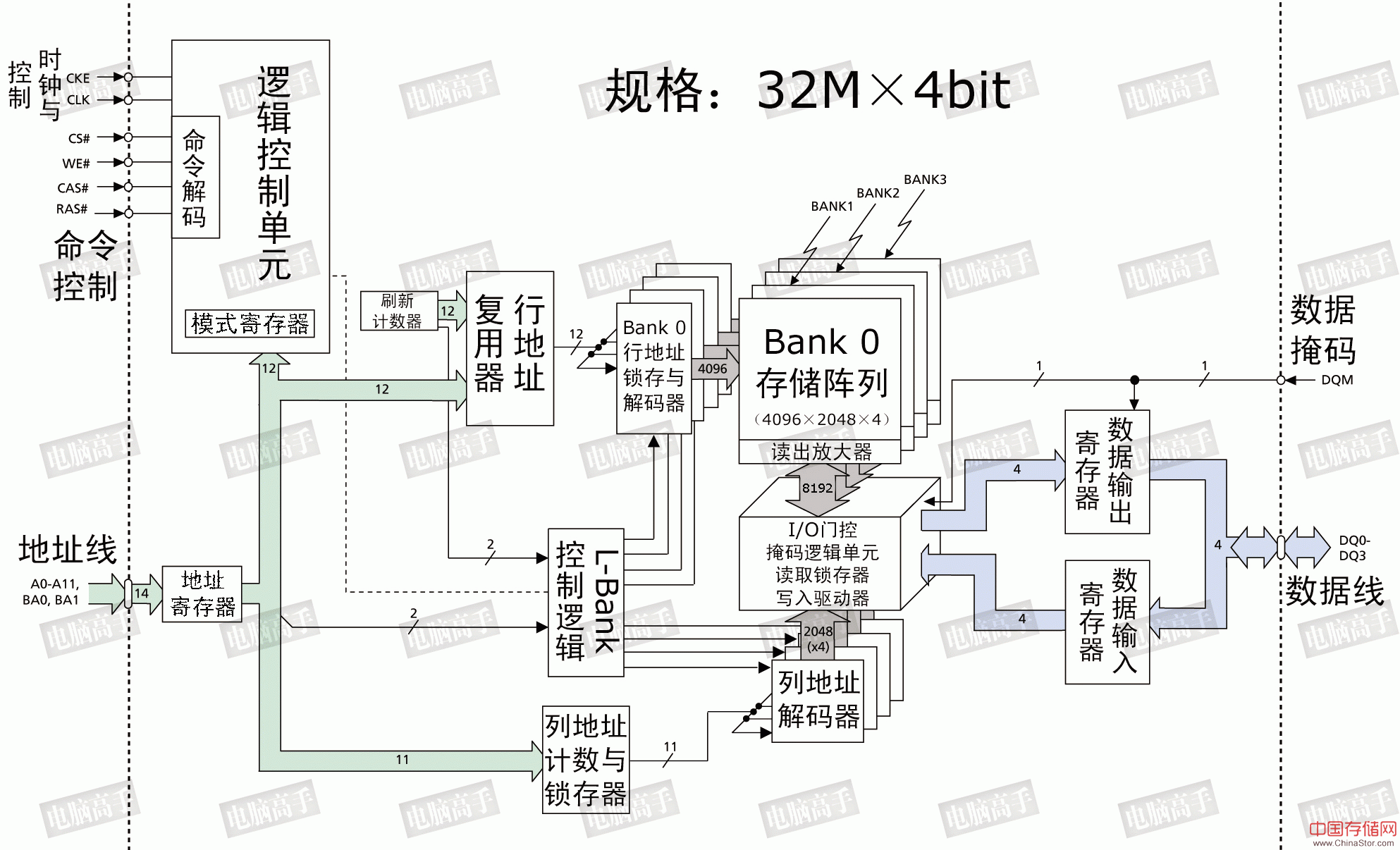
128Mbit(32M×4)SDRAM内部结构图
1、芯片初始化
可能很多人都想象不到,在SDRAM芯片内部还有一个逻辑控制单元,并且有一个模式寄存器为其提供控制参数。因此,每次开机时SDRAM都要先对这个控制逻辑核心进行初始化。有关预充电和刷新的含义在下文有讲述,关键的阶段就在于模式寄存器(MR,Mode Register)的设置,简称MRS(MR Set),这一工作由北桥芯片在BIOS的控制下进行,寄存器的信息由地址线来提供。

SDRAM在开机时的初始化过程
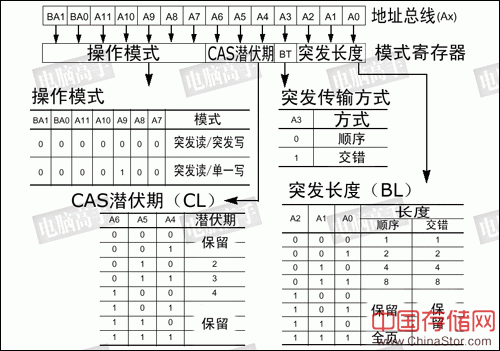
SDRAM模式寄存器所控制的操作参数:地址线提供不同的0/1信号来获得不同的参数。在设置到MR之后,就开始了进入正常的工作状态,图中相关参数将结合下文具体讲述
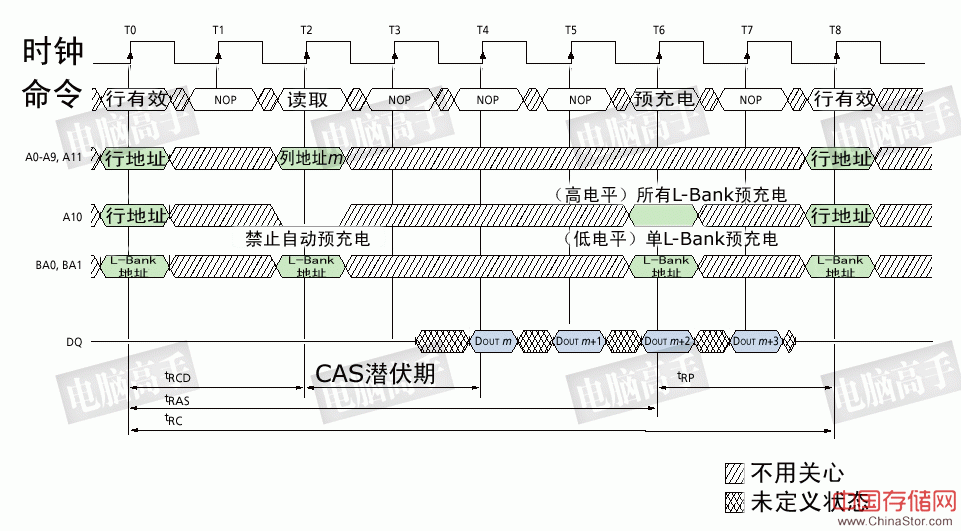
2、行有效
初始化完成后,要想对一个L-Bank中的阵列进行寻址,首先就要确定行(Row),使之处于活动状态(Active),然后再确定列。虽然之前要进行片选和L-Bank的定址,但它们与行有效可以同时进行。

行有效时序图
从图中可以看出,在CS#、L-Bank定址的同时,RAS(Row Address Strobe,行地址选通脉冲)也处于有效状态。此时An地址线则发送具体的行地址。如图中是A0-A11,共有12个地址线,由于是二进制表示法,所以共有4096个行(212=4096),A0-A11的不同数值就确定了具体的行地址。由于行有效的同时也是相应L-Bank有效,所以行有效也可称为L-Bank有效。
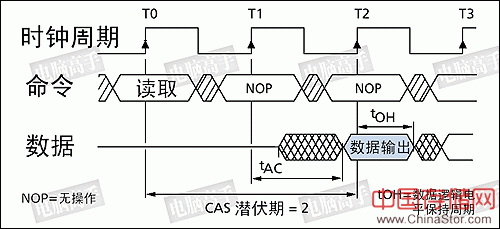
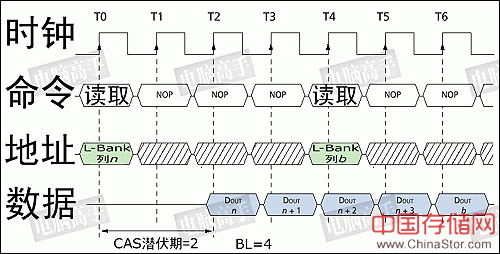
3、列读写
行地址确定之后,就要对列地址进行寻址了。但是,地址线仍然是行地址所用的A0-A11(本例)。没错,在SDRAM中,行地址与列地址线是共用的。不过,读/写的命令是怎么发出的呢?其实没有一个信号是发送读或写的明确命令的,而是通过芯片的可写状态的控制来达到读/写的目的。显然WE#信号就是一个关键。WE#无效时,当然就是读取命令。
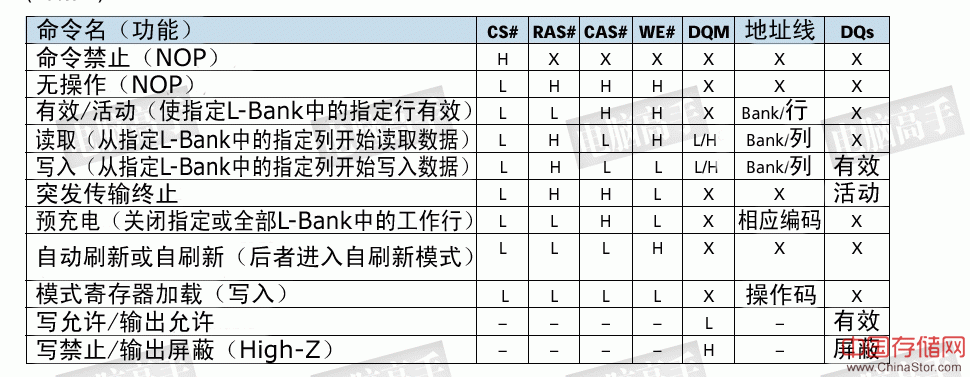 点击查看大图
点击查看大图
SDRAM基本操作命令,通过各种控制/地址信号的组合来完成(H代表高电平,L代表低电平,X表示高低电平均没有影响)。此表中,除了自刷新命令外,所有命令都是默认CKE有效。对于自刷新命令,下文有详解
列寻址信号与读写命令是同时发出的。虽然地址线与行寻址共用,但CAS(Column Address Strobe,列地址选通脉冲)信号则可以区分开行与列寻址的不同,配合A0-A9,A11(本例)来确定具体的列地址。

读写操作示意图,读取命令与列地址一块发出(当WE#为低电平是即为写命令)
然而,在发送列读写命令时必须要与行有效命令有一个间隔,这个间隔被定义为tRCD,即RAS to CAS Delay(RAS至CAS延迟),大家也可以理解为行选通周期,这应该是根据芯片存储阵列电子元件响应时间(从一种状态到另一种状态变化的过程)所制定的延迟。tRCD是SDRAM的一个重要时序参数,可以通过主板BIOS经过北桥芯片进行调整,但不能超过厂商的预定范围。广义的tRCD以时钟周期(tCK,Clock Time)数为单位,比如tRCD=2,就代表延迟周期为两个时钟周期,具体到确切的时间,则要根据时钟频率而定,对于PC100 SDRAM,tRCD=2,代表20ns的延迟,对于PC133则为15ns。

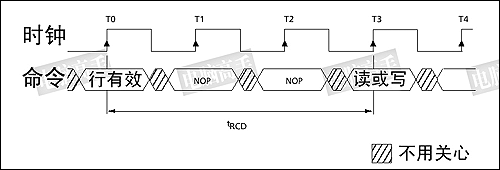
tRCD=3的时序图
|
#p#SDRAM与内存基础概念(五)#e# |
| SDRAM与内存基础概念(五)
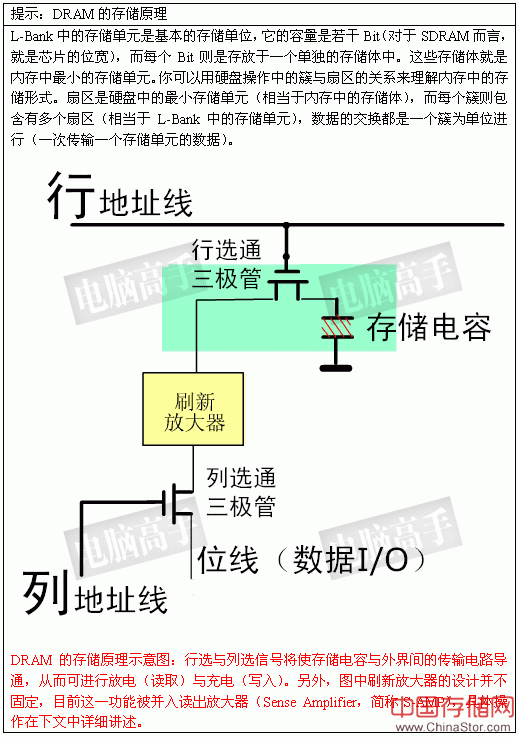
4、 数据输出(读) 在选定列地址后,就已经确定了具体的存储单元,剩下的事情就是数据通过数据I/O通道(DQ)输出到内存总线上了。但是在CAS发出之后,仍要经过一定的时间才能有数据输出,从CAS与读取命令发出到第一笔数据输出的这段时间,被定义为CL(CAS Latency,CAS潜伏期)。由于CL只在读取时出现,所以CL又被称为读取潜伏期(RL,Read Latency)。CL的单位与tRCD一样,为时钟周期数,具体耗时由时钟频率决定。 不过,CAS并不是在经过CL周期之后才送达存储单元。实际上CAS与RAS一样是瞬间到达的,但CAS的响应时间要更快一些。为什么呢?假设芯片位宽为n个bit,列数为c,那么一个行地址要选通n×c个存储体,而一个列地址只需选通n个存储体。但存储体中晶体管的反应时间仍会造成数据不可能与CAS在同一上升沿触发,肯定要延后至少一个时钟周期。 由于芯片体积的原因,存储单元中的电容容量很小,所以信号要经过放大来保证其有效的识别性,这个放大/驱动工作由S-AMP负责,一个存储体对应一个S-AMP通道。但它要有一个准备时间才能保证信号的发送强度(事前还要进行电压比较以进行逻辑电平的判断),因此从数据I/O总线上有数据输出之前的一个时钟上升沿开始,数据即已传向S-AMP,也就是说此时数据已经被触发,经过一定的驱动时间最终传向数据I/O总线进行输出,这段时间我们称之为tAC(Access Time from CLK,时钟触发后的访问时间)。tAC的单位是ns,对于不同的频率各有不同的明确规定,但必须要小于一个时钟周期,否则会因访问时过长而使效率降低。比如PC133的时钟周期为7.5ns,tAC则是5.4ns。需要强调的是,每个数据在读取时都有tAC,包括在连续读取中,只是在进行第一个数据传输的同时就开始了第二个数据的tAC。
CL=2与tAC示意图
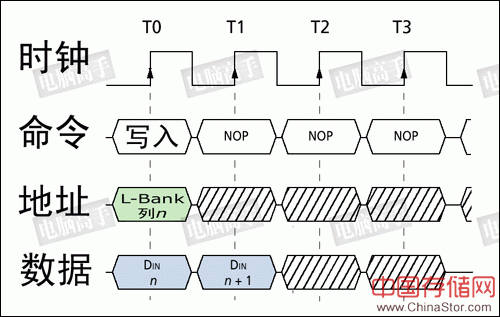
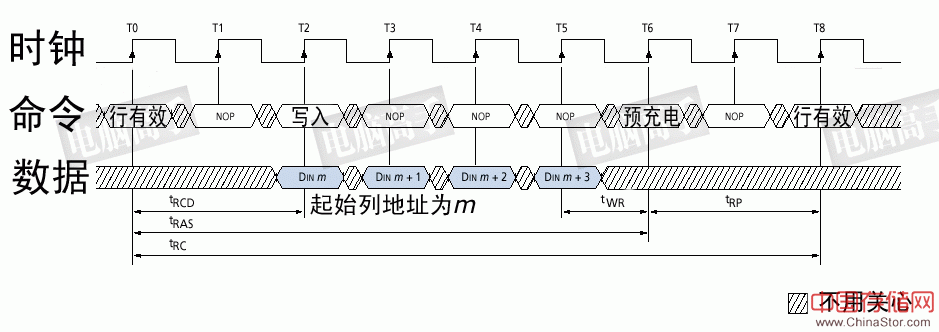
CL的数值不能超出芯片的设计规范,否则会导致内存的不稳定,甚至开不了机(超频的玩家应该有体会),而且它也不能在数据读取前临时更改。CL周期在开机初始化过程中的MRS阶段进行设置,在BIOS中一般都允许用户对其调整,然后BIOS控制北桥芯片在开机时通过A4-A6地址线对MR中CL寄存器的信息进行更改。 不过,从存储体的结构图上可以看出,原本逻辑状态为1的电容在读取操作后,会因放电而变为逻辑0。所以,以前的DRAM为了在关闭当前行时保证数据的可靠性,要对存储体中原有的信息进行重写,这个任务由数据所经过的刷新放大器来完成,它根据逻辑电平状态,将数据进行重写(逻辑0时就不重写),由于这个操作与数据的输出是同步进行互不冲突,所以不会产生新的重写延迟。后来通过技术的改良,刷新放大器被取消,其功能由S-AMP取代,因为在读取时它会保持数据的逻辑状态,起到了一个Cache的作用,再次读取时由它直接发送即可,不用再进行新的寻址输出,此时数据重写操作则可在预充电阶段完成。 5、数据输入(写) 数据写入的操作也是在tRCD之后进行,但此时没有了CL(记住,CL只出现在读取操作中),行寻址与列寻址的时序图和上文一样,只是在列寻址时,WE#为有效状态。
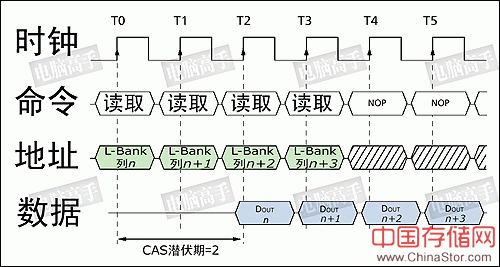
数据写入的时序图 从图中可见,由于数据信号由控制端发出,输入时芯片无需做任何调校,只需直接传到数据输入寄存器中,然后再由写入驱动器进行对存储电容的充电操作,因此数据可以与CAS同时发送,也就是说写入延迟为0。不过,数据并不是即时地写入存储电容,因为选通三极管(就如读取时一样)与电容的充电必须要有一段时间,所以数据的真正写入需要一定的周期。为了保证数据的可靠写入,都会留出足够的写入/校正时间(tWR,Write Recovery Time),这个操作也被称作写回(Write Back)。tWR至少占用一个时钟周期或再多一点(时钟频率越高,tWR占用周期越多),有关它的影响将在下文进一步讲述。 6、突发长度 突发(Burst)是指在同一行中相邻的存储单元连续进行数据传输的方式,连续传输所涉及到存储单元(列)的数量就是突发长度(Burst Lengths,简称BL)。 在目前,由于内存控制器一次读/写P-Bank位宽的数据,也就是8个字节,但是在现实中小于8个字节的数据很少见,所以一般都要经过多个周期进行数据的传输。上文讲到的读/写操作,都是一次对一个存储单元进行寻址,如果要连续读/写就还要对当前存储单元的下一个单元进行寻址,也就是要不断的发送列地址与读/写命令(行地址不变,所以不用再对行寻址)。虽然由于读/写延迟相同可以让数据的传输在I/O端是连续的,但它占用了大量的内存控制资源,在数据进行连续传输时无法输入新的命令,效率很低(早期的FPE/EDO内存就是以这种方式进行连续的数据传输)。为此,人们开发了突发传输技术,只要指定起始列地址与突发长度,内存就会依次地自动对后面相应数量的存储单元进行读/写操作而不再需要控制器连续地提供列地址。这样,除了第一笔数据的传输需要若干个周期(主要是之前的延迟,一般的是tRCD+CL)外,其后每个数据只需一个周期的即可获得。在很多北桥芯片的介绍中都有类似于X-1-1-1的字样,就是指这个意思,其中的X代表就代表第一笔数据所用的周期数。
非突发连续读取模式:不采用突发传输而是依次单独寻址,此时可等效于BL=1。虽然可以让数据是连续的传输,但每次都要发送列地址与命令信息,控制资源占用极大
突发连续读取模式:只要指定起始列地址与突发长度,寻址与数据的读取自动进行,而只要控制好两段突发读取命令的间隔周期(与BL相同)即可做到连续的突发传输 至于BL的数值,也是不能随便设或在数据进行传输前临时决定。在上文讲到的初始化过程中的MRS阶段就要对BL进行设置。目前可用的选项是1、2、4、8、全页(Full Page),常见的设定是4和8。顺便说一下,BL能否更改与北桥芯片的设计有很大关系,不是每个北桥都能像调整CL那样来调整BL。某些芯片组的BL是定死而不可改的,比如Intel芯片组的BL基本都为4,所以在相应的主板BIOS中也就不会有BL的设置选项。而由于目前的SDRAM系统的数据传输是以64bit/周期进行,所以在一些BIOS也把BL用QWord(4字,即64bit)来表示。如4QWord就是BL=4。
另外,在MRS阶段除了要设定BL数值之外,还要具体确定读/写操作的模式以及突发传输的模式。突发读/突发写,表示读与写操作都是突发传输的,每次读/写操作持续BL所设定的长度,这也是常规的设定。突发读/单一写,表示读操作是突发传输,写操作则只是一个个单独进行。突发传输模式代表着突发周期内所涉及到的存储单元的传输顺序。顺序传输是指从起始单元开始顺序读取。假如BL=4,起始单元编号是n,顺序就是n、n+1、n+2、n+3。交错传输就是打乱正常的顺序进行数据传输(比如第一个进行传输的单元是n,而第二个进行传输的单元是n+2而不是n+1),至于交错的规则在SDRAM规范中有详细的定义表,但在这此出于必要性与篇幅的考虑就不列出了。 #p#SDRAM与内存基础概念(六)#e# SDRAM与内存基础概念(六) 7、预充电 由于SDRAM的寻址具体独占性,所以在进行完读写操作后,如果要对同一L-Bank的另一行进行寻址,就要将原来有效(工作)的行关闭,重新发送行/列地址。L-Bank关闭现有工作行,准备打开新行的操作就是预充电(Precharge)。预充电可以通过命令控制,也可以通过辅助设定让芯片在每次读写操作之后自动进行预充电。实际上,预充电是一种对工作行中所有存储体进行数据重写,并对行地址进行复位,同时释放S-AMP(重新加入比较电压,一般是电容电压的1/2,以帮助判断读取数据的逻辑电平,因为S-AMP是通过一个参考电压与存储体位线电压的比较来判断逻辑值的),以准备新行的工作。具体而言,就是将S-AMP中的数据回写,即使是没有工作过的存储体也会因行选通而使存储电容受到干扰,所以也需要S-AMP进行读后重写。此时,电容的电量(或者说其产生的电压)将是判断逻辑状态的依据(读取时也需要),为此要设定一个临界值,一般为电容电量的1/2,超过它的为逻辑1,进行重写,否则为逻辑0,不进行重写(等于放电)。为此,现在基本都将电容的另一端接入一个指定的电压(即1/2电容电压),而不是接地,以帮助重写时的比较与判断。 现在我们再回过头看看读写操作时的命令时序图,从中可以发现地址线A10控制着是否进行在读写之后当前L-Bank自动进行预充电,这就是上文所说的“辅助设定”。而在单独的预充电命令中,A10则控制着是对指定的L-Bank还是所有的L-Bank(当有多个L-Bank处于有效/活动状态时)进行预充电,前者需要提供L-Bank的地址,后者只需将A10信号置于高电平。 在发出预充电命令之后,要经过一段时间才能允许发送RAS行有效命令打开新的工作行,这个间隔被称为tRP(Precharge command Period,预充电有效周期)。和tRCD、CL一样,tRP的单位也是时钟周期数,具体值视时钟频率而定。
读取时预充电时序图:图中设定:CL=2、BL=4、tRP=2。自动预充电时的开始时间与此图一样,只是没有了单独的预充电命令,并在发出读取命令时,A10地址线要设为高电平(允许自动预充电)。可见控制好预充电启动时间很重要,它可以在读取操作结束后立刻进入新行的寻址,保证运行效率。 误区:读写情况下都要考虑写回延迟 有些文章强调由于写回操作而使读/写操作后都有一定的延迟,但从本文的介绍中写可以看出,即使是读后立即重写的设计,由于是与数据输出同步进行,并不存在延迟。只有在写操作后进行其他的操作时,才会有这方面的影响。写操作虽然是0延迟进行,但每笔数据的真正写入则需要一个足够的周期来保证,这段时间就是写回周期(tWR)。所以预充电不能与写操作同时进行,必须要在tWR之后才能发出预充电命令,以确保数据的可靠写入,否则重写的数据可能是错的,这就造成了写回延迟。
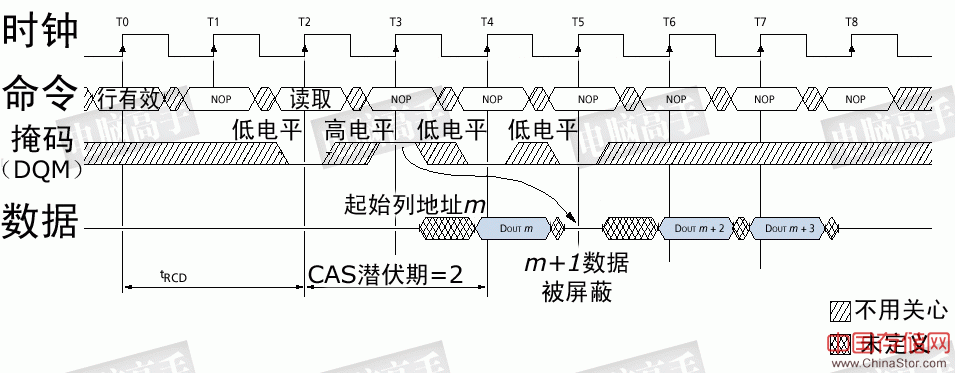
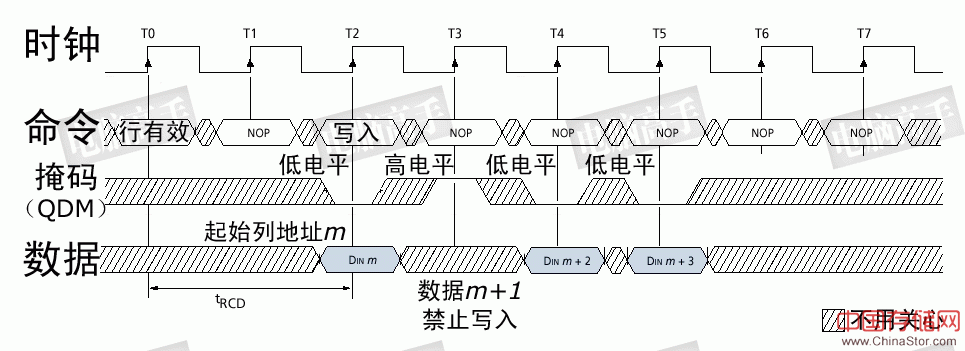
数据写入时预充电操作时序图:注意其中的tWR参数,由于它的存在,使预充电操作延后,从而造成写回延迟 8、刷新 之所以称为DRAM,就是因为它要不断进行刷新(Refresh)才能保留住数据,因此它是DRAM最重要的操作。 刷新操作与预充电中重写的操作一样,都是用S-AMP先读再写。但为什么有预充电操作还要进行刷新呢?因为预充电是对一个或所有L-Bank中的工作行操作,并且是不定期的,而刷新则是有固定的周期,依次对所有行进行操作,以保留那些久久没经历重写的存储体中的数据。但与所有L-Bank预充电不同的是,这里的行是指所有L-Bank中地址相同的行,而预充电中各L-Bank中的工作行地址并不是一定是相同的。 那么要隔多长时间重复一次刷新呢?目前公认的标准是,存储体中电容的数据有效保存期上限是64ms(毫秒,1/1000秒),也就是说每一行刷新的循环周期是64ms。这样刷新速度就是:行数量/64ms。我们在看内存规格时,经常会看到4096 Refresh Cycles/64ms或8192 Refresh Cycles/64ms的标识,这里的4096与8192就代表这个芯片中每个L-Bank的行数。刷新命令一次对一行有效,发送间隔也是随总行数而变化,4096行时为15.625μs(微秒,1/1000毫秒),8192行时就为7.8125μs。 刷新操作分为两种:自动刷新(Auto Refresh,简称AR)与自刷新(Self Refresh,简称SR)。不论是何种刷新方式,都不需要外部提供行地址信息,因为这是一个内部的自动操作。对于AR, SDRAM内部有一个行地址生成器(也称刷新计数器)用来自动的依次生成行地址。由于刷新是针对一行中的所有存储体进行,所以无需列寻址,或者说CAS在RAS之前有效。所以,AR又称CBR(CAS Before RAS,列提前于行定位)式刷新。由于刷新涉及到所有L-Bank,因此在刷新过程中,所有L-Bank都停止工作,而每次刷新所占用的时间为9个时钟周期(PC133标准),之后就可进入正常的工作状态,也就是说在这9 个时钟期间内,所有工作指令只能等待而无法执行。64ms之后则再次对同一行进行刷新,如此周而复始进行循环刷新。显然,刷新操作肯定会对SDRAM的性能造成影响,但这是没办法的事情,也是DRAM相对于SRAM(静态内存,无需刷新仍能保留数据)取得成本优势的同时所付出的代价。 SR则主要用于休眠模式低功耗状态下的数据保存,这方面最著名的应用就是STR(Suspend to RAM,休眠挂起于内存)。在发出AR命令时,将CKE置于无效状态,就进入了SR模式,此时不再依靠系统时钟工作,而是根据内部的时钟进行刷新操作。在SR期间除了CKE之外的所有外部信号都是无效的(无需外部提供刷新指令),只有重新使CKE有效才能退出自刷新模式并进入正常操作状态。 9、数据掩码 在讲述读/写操作时,我们谈到了突发长度。如果BL=4,那么也就是说一次就传送4×64bit的数据。但是,如果其中的第二笔数据是不需要的,怎么办?还都传输吗?为了屏蔽不需要的数据,人们采用了数据掩码(Data I/O Mask,简称DQM)技术。通过DQM,内存可以控制I/O端口取消哪些输出或输入的数据。这里需要强调的是,在读取时,被屏蔽的数据仍然会从存储体传出,只是在“掩码逻辑单元”处被屏蔽。DQM由北桥控制,为了精确屏蔽一个P-Bank位宽中的每个字节,每个DIMM有8个DQM信号线,每个信号针对一个字节。这样,对于4bit位宽芯片,两个芯片共用一个DQM信号线,对于8bit位宽芯片,一个芯片占用一个DQM信号,而对于16bit位宽芯片,则需要两个DQM引脚。 SDRAM官方规定,在读取时DQM发出两个时钟周期后生效,而在写入时,DQM与写入命令一样是立即成效。
读取时数据掩码操作,DQM在两个周期后生效,突发周期的第二笔数据被取消
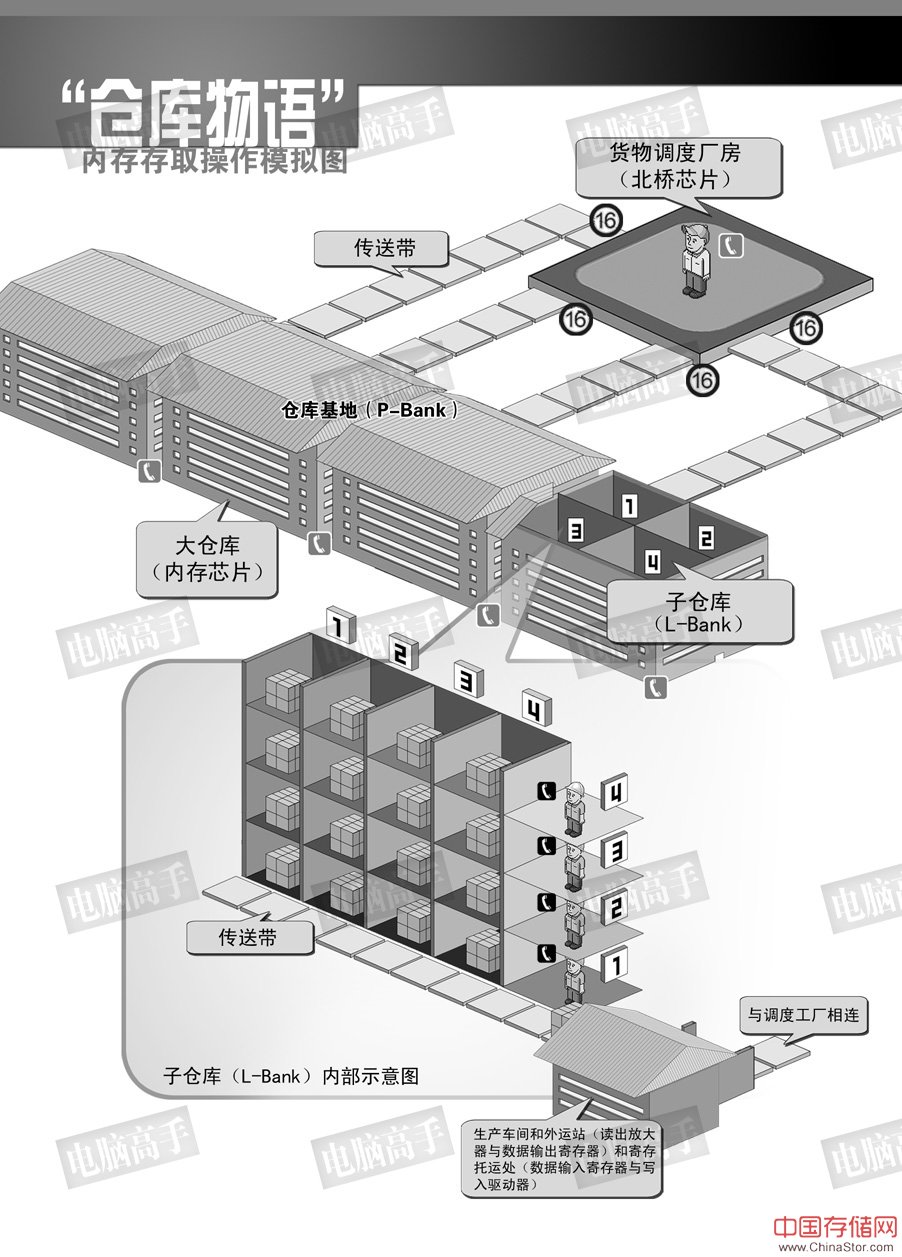
写入时数据掩码操作,DQM立即生效,突发周期的第二笔数据被取消 有关内存内部的基本操作就到此结束,其实还有很多内存的操作没有描述,但都不是很重要了,限于篇幅与必要性,我们不在此介绍,有兴趣的读者可以自行查看相关资料。 仓库物语 货物基地(主板)连接着物资(数据)的供求方。基地的货物调度厂房(北桥芯片)掌管着若干个用于临时供货/生产与存储的仓库基地(P-Bank),它们通常隶属于某一仓储集团(DIMM),这种基地与调度厂房之间必须由64条传送带联系着(P-Bank位宽),每条传送带一次只能运送一个标准的货物(1bit数据),而且一次至少要传送64个标准货物,这是它们之间的约定,仓库基地必须满足。
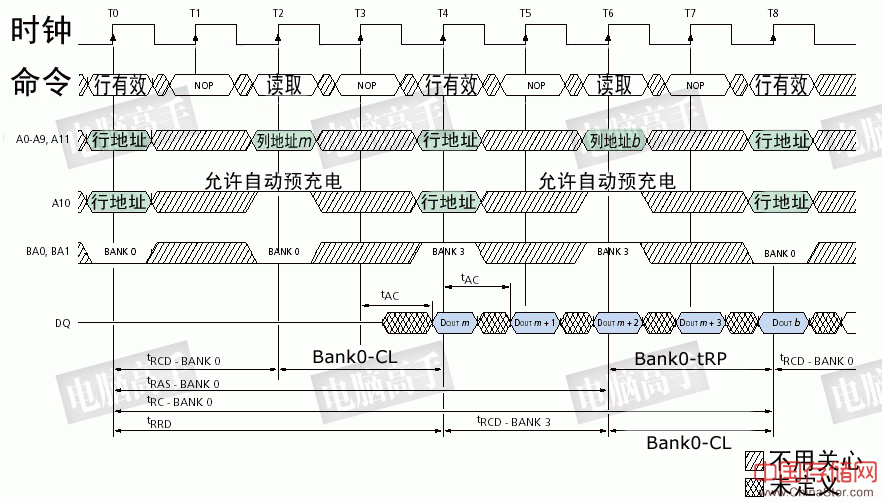
上图就是这样的一个仓库基地(P-Bank),它由4个大仓库(内存芯片)组成,它们的规模都相当大,每个大仓库为基地提供16条传送带(芯片位宽为16bit),总共加起来刚好就是64条。每个大仓库里都有四个规模和结构相同的子仓库(L-Bank),它们都被统一编了号。而子仓库中有很多层(行),每层里又有很多的储藏间(列),每个储藏间可以放置16个标准货物,虽然子仓库的规模很大,但每一层和每一个房间也都编好了号,而且每一层都有一个搬运工在值班。 为了与外界联系方便,仓储集团与调度室设置了专线电话,和一个国家一样,每个仓库基地有一个区号(片选),另外还有四个子仓库号码(L-Bank地址),是所有大仓库共享的,一个号码对应所有大仓库中编号相同的子仓库。而专线电话的数量也是四个,这样可保证与某个子仓库通话时不会妨碍给其他子仓库打电话。在子仓库的每层则设立分机给搬运工使用。子仓库的楼下就是传送带,找到货物把它扔到上面。但每个大仓库只有一个传送带,也就是说同一时间内只能有一个子仓库在工作。每个子仓库都有一个自己的生产车间(读出放大器)负责指定货物的生产,并且每个大仓库都有一个外运站(数据输出寄存器)和寄存托运处(数据输入寄存器与写入驱动器)与传送带相连,前者负责货物的输出中转,后者负责所接受货物并寄存然后帮助搬运工运送到指定储藏间。那么它是如何与调度厂房协同工作的呢? 1、需求方有货物请求了,这个请求发送到调度厂房,调度人员开根据货主的要求给指定的子仓库打电话,电话号码是:区号+子仓库号码+楼层分机(片选+L-Bank寻址+行有效/选通)。那一层的搬运工接到电话后就开始准备工作。 2、当搬运工点亮所有储藏间的门牌(tRCD)之后,调度人员会告诉搬运工,货物放在哪个储藏间里(列寻址),如果货物很多,并且是连续存放的,调度员会通知搬运工:“一会儿要搬的时候,从起始房间开始连续将后面的n个房间的货物都搬出来,我就不再重复了”(突发传输)。但是,他告诉搬运工要等一下,要求所有大仓库的人员统一行动,先别出货。 3、根据事先的规定,搬运工在经过指定的时间后开始将货物扔到传送带上,传送带开始运转并将货物送到生产车间,由它来复制出全新的货物,然后再送到传送带上通过外运站向调度厂房运去。人们通常把从搬运工找到具体储藏间开始,到货物真正出现在送往调度厂房的传送带上的这段时间称之为“输出潜伏期”(CL),而从值班人把货物扔到传送带到货物开始传向调度厂房的这段时间,被称为“货物输出延迟”(tAC),它体现了值班人员的反应时间和生产车间的效率,也影响着仓库基地所在集团(DIMM)的名声。 4、在这个搬运工工作的同时,由于电话对于编号相同的子仓库是并联的,所以其他子仓库相同楼层的搬运工也收到相同的命令,从相同编号的房间搬出货物,运向各自的生产车间。此时,同一批货物同时出现在各自的16条传送带上,并整齐地向调度厂房运去。 5、当货物传送完后,原始货物还要送回储藏间保管,这是必须的,但如果没有要求,货物可以一直保留在生产车间,如果再有需要就再生产,而不用再麻烦搬运工了(读出放大器相当于一个Cache)。调度人员接着会进行下一批货物的调度,当他发现下一批货物在上次操作的子仓库中,但不在刚才通话的那一层,只能再重新拨电话。这时,他通知各子仓库货物翻新运回,清理生产车间,之后挂断电话(预充电命令),这一切必须要在指定时间里(tRP)完成,然后才能给新的楼层打电话。搬运员接到通知后,就将这一 层中所有房间的货物都拿到生产车间进行翻新(没有货物的就不用翻新),然后再搬回储藏间。干完这一切之后,搬运工挂了电话(关闭行)就可以休息了,他们称这种工作为“货物清理返运”(预充电)。这个工作的速度也要快,否则同样会影响集团名声。当然,这个工作可以让搬运工自动完成(自动预充电),只需调度员在当初下搬运指令时提醒一他:“货物运送完了,就进行货物清理返运吧,我不管了”(用A10地址线)。 6、当有货物要运来存储时,调度员在向子仓库发送货物的同时就给指定的楼层打电话,让他们准备好房间,此时货物已经到了寄存托运处,没有任何的运送延迟(写入延迟=0),搬运工在托运间的帮助下,向指定的储藏间运送货物,这可需要一定的时间了,他们称之为货物堆放时间(tWR),必须给足搬运工们这一时间,而不能在这期间里让他们干其他的工作,否则他们会令货物丢失并罢-工…… (注:本插栏是对DRAM操作的形象性描述,谨供辅助性理解本专题,严谨的操作说明见上文。另外,在此请各位读者注意,将内存比喻为仓库只是为了形象化描述,而不要把内存等同理解为存储,它们是有本质的不同的,在本文的比喻中,它只是一个临时性仓库,这一点请大家分清,不要因此产生新的错误概念。) #p#SDRAM的结构、时序与性能的关系(上)#e# SDRAM的结构、时序与性能的关系(上) 在讲完SDRAM的基本工作原理和主要操作之后,我们现在要重要分析一下SDRAM的时序与性能之间的关系,它不在局限于芯片本身,而是从整体的内存系统去分析。这也是广大DIYer所关心的话题。比如CL值对性能的影响有多大几乎是每个内存论坛都会有讨论,今天我们就详细探讨一下,其中的很多内容同样适用于DDR与RDRAM。这里需要强调一点,对于内存系统整体而言,一次内存访问就是对一个页的访问,这个页的定义已经在解释Full Page含义时讲明了。由于在P-Bank中,每个芯片的寻址都是一样的,所以可以将页访问“浓缩”等效为对每芯片中指定行的访问,这样可能比较好理解。但为了与官方标准统一,在下文中会经常用页来描述相关的内容,请读者注意理解。 一、影响性能的主要时序参数 所谓的影响性能是并不是指SDRAM的带宽,频率与位宽固定后,带宽也就不可更改了。但这是理想的情况,在内存的工作周期内,不可能总处于数据传输的状态,因为要有命令、寻址等必要的过程。但这些操作占用的时间越短,内存工作的效率越高,性能也就越好。 非数据传输时间的主要组成部分就是各种延迟与潜伏期。通过上文的讲述,大家应该很明显看出有三个参数对内存的性能影响至关重要,它们是tRCD、CL和tRP。每条正规的内存模组都会在标识上注明这三个参数值,可见它们对性能的敏感性。 以内存最主要的操作——读取为例。tRCD决定了行寻址(有效)至列寻址(读/写命令)之间的间隔,CL决定了列寻址到数据进行真正被读取所花费的时间,tRP则决定了相同L-Bank中不同工作行转换的速度。现在可以想象一下读取时可能遇到的几种情况(分析写入操作时不用考虑CL即可): 1、要寻址的行与L-Bank是空闲的。也就是说该L-Bank的所有行是关闭的,此时可直接发送行有效命令,数据读取前的总耗时为tRCD+CL,这种情况我们称之为页命中(PH,Page Hit)。 2、要寻址的行正好是前一个操作的工作行,也就是说要寻址的行已经处于选通有效状态,此时可直接发送列寻址命令,数据读取前的总耗时仅为CL,这就是所谓的背靠背(Back to Back)寻址,我们称之为页快速命中(PFH,Page Fast Hit)或页直接命中(PDH,Page Direct Hit)。 3、要寻址的行所在的L-Bank中已经有一个行处于活动状态(未关闭),这种现象就被称作寻址冲突,此时就必须要进行预充电来关闭工作行,再对新行发送行有效命令。结果,总耗时就是tRP+tRCD+CL,这种情况我们称之为页错失(PM,Page Miss)。 显然,PFH是最理想的寻址情况,PM则是最糟糕的寻址情况。上述三种情况发生的机率各自简称为PHR——PH Rate、PFDR——PFH Rate、PMR——PM Rate。因此,系统设计人员(包括内存与北桥芯片)都尽量想提高PHR与PFHR,同时减少PMR,以达到提高内存工作效率的目的。 二、增加PHR的方法 显然,这与预充电管理策略有着直接的关系,目前有两种方法来尽量提高PHR。自动预充电技术就是其中之一,它自动的在每次行操作之后进行预充电,从而减少了日后对同一L-Bank不同行寻址时发生冲突的可能性。但是,如果要在当前行工作完成后马上打开同一L-Bank的另一行工作时,仍然存在tRP的延迟。怎么办? 此时就需要L-Bank交错预充电了。 VIA的4路交错式内存控制就是在一个L-Bank工作时,对下一个要工作的L-Bank进行预充电。这样,预充电与数据的传输交错执行,当访问下一个L-Bank时,tRP已过,就可以直接进入行有效状态了。目前VIA声称可以跨P-Bank进行16路内存交错,并以LRU算法进行预充电管理。 有关L-Bank交错预充电(存取)的具体执行在本刊2001年第2期已有详细介绍,这里就不再重复了。
L-Bank交错自动预充电/读取时序图:L-Bank 0与L-Bank 3实现了无间隔交错读取,避免了tRP对性能的影响
三、增加PFHR的方法 无论是自动预充电还是交错工作的方法都无法消除tRCD所带来的延迟。要解决这个问题,就要尽量让一个工作行在进行预充电前尽可能多的接收多个工作命令,以达到背靠背的效果,此时就只剩下CL所造成的读取延迟了(写入时没有延迟)。 如何做到这一点呢?这就是北桥芯片的责任了。在上文的时序图中有一个参数tRAS(Active to Precharge Command,行有效至预充电命令间隔周期)。它有一个范围,对于PC133标准,一般是预充电命令至少要在行有效命令5个时钟周期之后发出,最长间隔视芯片而异(基本在120000ns左右),否则工作行的数据将有丢失的危险。那么这也就意味着一个工作行从有效(选通)开始,可以有120000ns的持续工作时间而不用进行预充电。显然,只要北桥芯片不发出预充电(包括允许自动预充电)的命令,行打开的状态就会一直保持。在此期间的对该行的任何读写操作也就不会有tRCD的延迟。可见,如果北桥芯片在能同时打开的行(页)越多,那么PFHR也就越大。需要强调的是,这里的同时打开不是指对多行同时寻址(那是不可能的),而是指多行同时处于选通状态。我们可以看到一些SDRAM芯片组的资料中会指出可以同时打开多少个页的指标,这可以说是决定其内存性能的一个重要因素。
Intel 845芯片组MCH的资料:其中表明它可以支持24个页面同时处于打开状态 但是,可同时打开的页数也是有限制的。从SDRAM的寻址原理讲,同一L-Bank中不可能有两个打开的行(S-AMP只能为一行服务),这就限制了可同时打开的页面总数。以SDRAM有4个L-Bank,北桥最多支持8个P-Bank为例,理论上最多只能有32个页面能同时处于打开的状态。而如果只有一个P-Bank,那么就只剩下8个页面,因为有几个L-Bank才能有同时打开几个行而互不干扰。Intel 845的MHC虽然可以支持24个打开的页面,那也是指6个P-Bank的情况下(845MCH只支持6个P-Bank)。可见845已经将同时打开页数发挥到了极致。 不过,同时打开页数多了,也对存取策略提出了一定的要求。理论上,要尽量多地使用已打开的页来保证最短的延迟周期,只有在数据不存在(读取时)或页存满了(写入时)再考虑打开新的指定页,这也就是变向的连续读/写。而打开新页时就必须要关闭一个打开的页,如果此时打开的页面已是北桥所支持的最大值但还不到理论极限的话,就需要一个替换策略,一般都是用LRU算法来进行,这与VIA的交错控制大同小异。
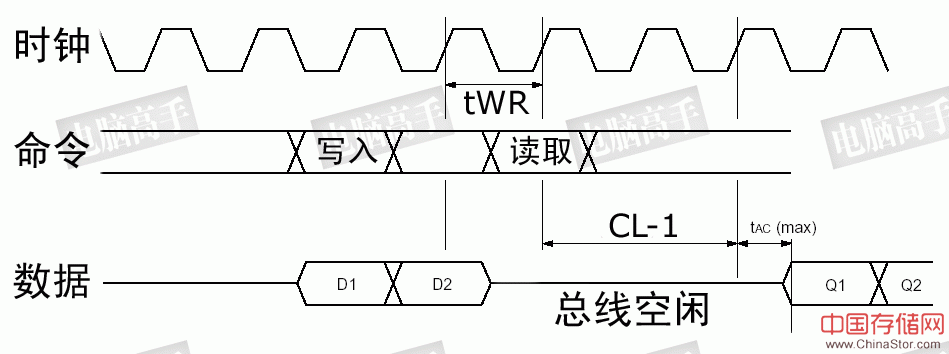
#p#SDRAM的结构、时序与性能的关系(下)#e#SDRAM的结构、时序与性能的关系(下) 四、内存结构对PHR的影响 这是结构设计上的问题,所以单独来说。在我们介绍L-Bank时,曾经提到单一的L-Bank会造成严重的寻址冲突。现在,当我们了解了内存寻址的原理后,就不难理解这句话了。如果只有一个L-Bank,那么除非是背靠背式的操作(PFH),否则tRP、tRCD、CL(读取时)一个也少不了。 上文中,内存交错之所以能实现就是因为有多个L-Bank,从这点就可以看出L-Bank数量与页命中率之间的关系了。PHR基本上可以等于“(L-Bank数-1)/L-Bank数”。 SDRAM有4个L-Bank,那么页命中率就是75%,DDR-Ⅱ SDRAM最多将有8个L-Bank,PHR最高为87.5%。而RDRAM则最多有32个L-Bank,PHR到了惊人的96.875%,这也是当时RDRAM攻击SDRAM的一主要方面。 不过,从内存的结构图上可以看出,L-Bank多了,相应外围辅助的元件也要增加,比如S-AMP,L-Bank地址线等等。在RDRAM的介绍中,我会讲到L-Bank数量增多后所带来的一些新问题。 五、读/写延迟不同对性能所造成的影响 SDRAM在读取操作时会有CL造成的延迟,而在写入时则是0延迟。这样,在读操作之后马上进行写操作的话,由于没有写延迟,数据线不会出现空闲的时候,保证了数据总线的利用率。但是,若在写操作之后马上进行读操作的话,即使是背靠背式进行,仍然会由于tWR与CL的存在而造成间隔,这期间数据总线将是空闲的,利用率受到了影响。
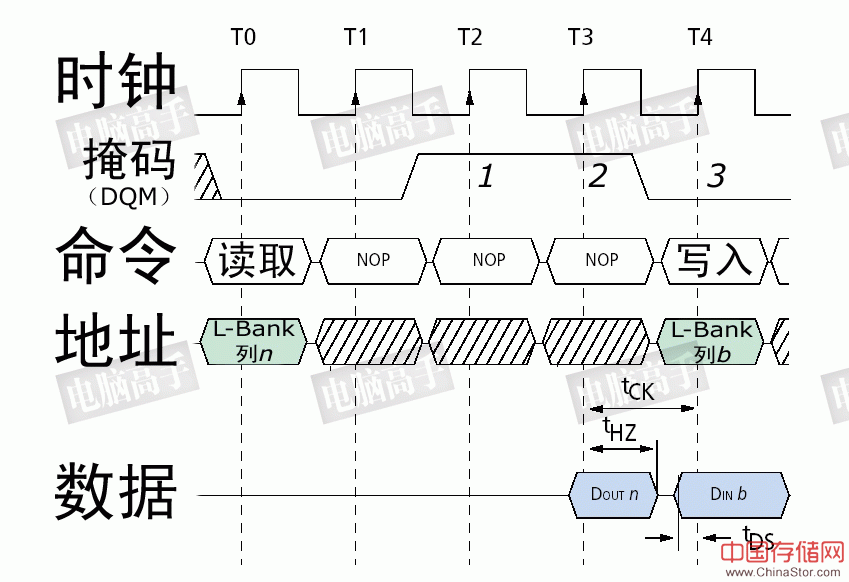
在先写后读的操作中,由于保证写入的可靠性,读取命令在tWR之后发出,并再经过CL才能输出数据,本例中CL=3,造成了两个时钟周期的总线空闲 这里需要着重说明一下,在突发读取过程中,想立刻中断并进行新的读操作,和读后读模式(见“突发连续读取模式图”)一样,只是新的读命令根据需要提前若干个周期发出,经过CL后就会自动传输新的数据。但是,若想中断读后立即进行写操作,就需要数据掩码(DQM)来屏蔽写入命令发出时的数据输出,避免总线冲突。根据芯片设计的不同,有时可能会浪费一个周期进行总线I/O的调转,此时一个周期的总线空闲也是不可避免的。
突发读后写时的操作,以本图为例,在最后一个所需数据(本例为第一笔数据)输出前一个周期使DQM有效,屏蔽第二笔数据的输出;2、发出写入命令,此时所读取的第二笔数据被屏蔽。3、继续DQM以屏蔽第三笔数据的输出。其中tHZ表示输出数据与外部电路的连接周期,tDS表示数据输入准备时间,如果tHZ+tDS>tCK,那么写入操作就要延后一个周期,这要视芯片的具体设计而定
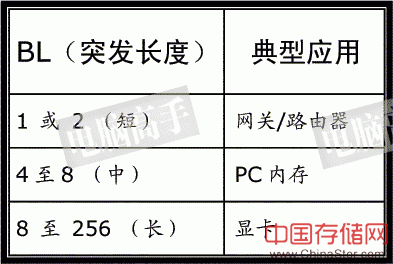
六、BL对性能的影响 从读/写之间的中断操作我们又引出了BL(突发长度)对性能影响的话题。首先,BL的长短与其应用的领域有着很大关系,下表就是目前三个主要的内存应用领域所使用的BL,这是厂商们经过多年的实践总结出来的。 BL与相应的工作领域
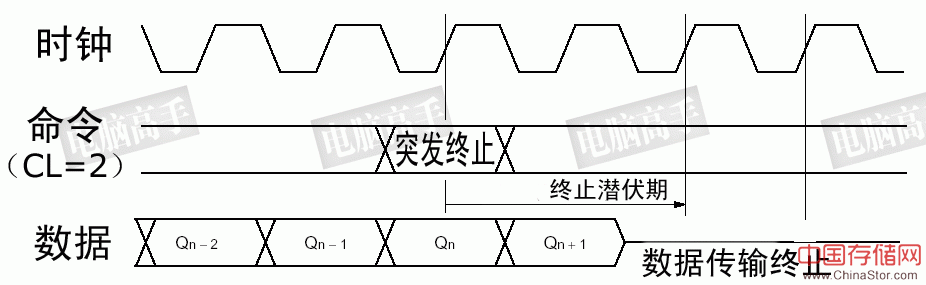
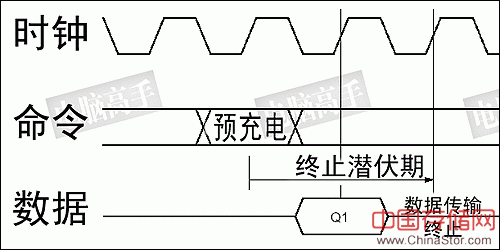
BL越长,对于连续的大数据量传输很有好处,但是对零散的数据,BL太长反而会造成总线周期的浪费。以P-Bank位宽64bit为例,BL=4时,一个突发操作能传输32字节的数据,但如果只需要前16个字节,后两个周期是无效的。如果需要40字节,需要再多进行一次突发传输,但实际只需要一个传输周期就够了,从而浪费了三个传输周期。而对于2KB的数据,BL=4的设置意味着要每隔4个周期发送新的列地址,并重复63次。而对于BL=256,一次突发就可完成,并且不需要中途再进行控制。不少人都因此表示了BL设定对性能影响的担心。 但设计人员也不是傻瓜,通过上文的介绍,可以看出他们在这方面的考虑。通过写命令、DQM、读命令的配合/操作,完全可以任意地中断突发周期开始新的操作,而且DQM还可以帮我们在BL中选择有用的数据,从而最大限度降低突发传输对性能带来的影响。另外,预充电命令与专用的突发传输终止命令都可以用来中断BL,前者在中断后进行预充电,后者在中断后不进行其他读/写操作。
专用的突发停止命令可用来中断突发读取,其生效潜伏期与CL相同。对于写入则立即有效
用预充电命令来中断突发读取,生效潜伏期与CL相同,要小于或等于tRP。写入时预充电在最后一个有效写入周期完成,并经过tWR之后发出,同时立即中断突发传输 所以,突发周期的中断并不难,但用短BL应付大数据量存取需要不断的指令与列寻址配合,而为了取消不需要的传输周期,由于需要运用额外的控制,也将占用不少的控制资源。所以BL针对不同应用领域有不同设计的主要目的,就是在保证性能的同时,系统控制资源也能得到合理的运用。 |





声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。
































