广告和新闻推荐的共同和不同点:相同点,它们都可以视为都可看做一个点击率(ctr)估计的任务;不同点,推荐产生的点击率可能是广告的10到100倍,同时在特征描述上,广告通常细粒度特征,推荐对应的则是相对粗粒度。
今晚(北京时间7月30日)20:30,继“
YARN or Mesos?Spark痛点探讨”、“
Mesos资源调度与管理的深入分享与交流”、“
主流SQL on Hadoop框架选择”和“
Hadoop/Spark在七牛数据平台的实战(稍后放出分享详情)”之后,CSDN Spark微信用户群将进行第五次讨论,届时李滔与大家分享“推荐算法和Spark实现”实战,并与用户互动。
嘉宾简介

李滔 搜狐大数据中心技术经理
李滔,中国科技大学博士毕业。曾就职于理光北京研究所以及Teradata公司。在理光期间设计了理光相机的第一代人脸检测/对焦系统。之后在Teradata公司从事大规模数据挖掘的算法设计开发,基于Teradata Aster的Map/Reduce和图计算平台设计实现了多种机器学习/数据挖掘算法并成功应用于商业实践。目前在搜狐大数据中心用户推荐部从事推荐和广告算法研发工作。目前关注的技术方向为广告技术、并行计算和大数据分析。
分享简介
广告和新闻推荐的共同和不同点:相同点,它们都可以视为都可看做一个点击率(ctr)估计的任务,其特征都包含了用户、商品、上下文三个维度,同时点击率也是动态变化的;不同点,推荐产生的点击率可能是广告的10到100倍,同时在特征描述上,广告通常是细粒度特征,而推荐对应的则是相对粗粒度。
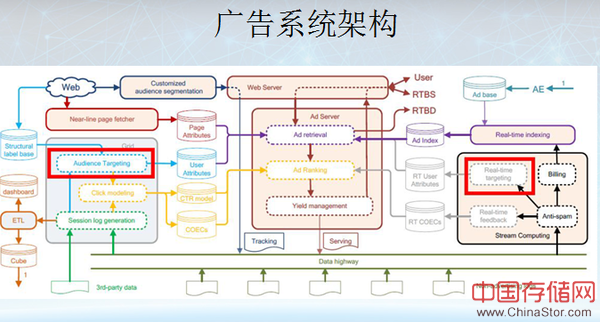
在广告系统架构中,推荐有很多类似的地方,上面是用户的广告请求,包括一些时时交易的请求会从上面过来。同时,整个系统分为左、中、右3个部分:左边主要是关于离线模型,像用户地位,用户定向,这些主要是从日志数据、历史点击数据提炼出来,比如用户的喜好,或者是一些地理信息这些。这一类型的数据会送到下面,这个离线模型会用来做广告点击率的预估。右边是实时流处理部分,做一些短期行为和长期行为对比,其中会有一个模块,通过用户实时的短期行为估计他的定向。这里重要的是有一个广告的实时索引,因为对像搜狐这样的门户来讲,广告主的数量比较大,可能对每一条广告过来之后做一个实时排序,结合这个页面的信息,还有用户的信息,然后通过一个索引检索出可能是用户感兴趣的广告。这部分可能的侯选的广告会进入到黄色的部分,排序好了之后会综合考虑到广告的点击率和广告主的出价。排序得到结果之后,下面有一个模块,这个模块主要是做广告投放策略控制,比如现在是出基本广告还是出展示广告。
参与方式
1. 微信群2已超过100人,请扫下方二维码,工作人员会邀请进入。(注:CSDN Spark用户微信群1已满500,正在清理并邀请2群用户进入,分享和讨论将在群1中进行,QQ群和微信群同步直播)

2. 加入CSDN Spark技术交流QQ群,群号:213683328。
3. CSDN高端专家微信群,采取受邀加入方式,不惧高门槛的请加微信号“zhongyineng”或扫描下方二维码,PS:带上你的BIO。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。