将Spark部署到Hadoop 2.2.0上需要经过以下几步:步骤1:准备基础软件,步骤2:下载编译spark 0.8.1或者更高版本,步骤3:运行Spark实例。
本文介绍的是如何将Apache Spark部署到Hadoop 2.2.0上,如果你们的Hadoop是其他版本,比如CDH4,可直接参考官方说明操作。
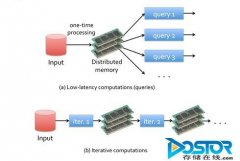
需要注意两点:(1)使用的Hadoop必须是2.0系列,比如0.23.x,2.0.x,2.x.x或CDH4、CDH5等,将Spark运行在 Hadoop上,本质上是将Spark运行在Hadoop YARN上,因为Spark自身只提供了作业管理功能,资源调度要依托于第三方系统,比如YARN或Mesos等 (2)之所以不采用Mesos而是YARN,是因为YARN拥有强大的社区支持,且逐步已经成为资源管理系统中的标准。
注意,目前官方已经发布了0.8.1版本,可以直接从这里选择合适的版本下载,如果你使用的是hadoop 2.2.0或者CDH5,可以直接从这里下载。
将Spark部署到Hadoop 2.2.0上需要经过以下几步:
步骤1:准备基础软件
步骤2:下载编译spark 0.8.1或者更高版本
步骤3:运行Spark实例
接下来详细介绍这几个步骤。
步骤1:准备基础软件
(1) 基本软件
包括linux操作系统、Hadoop 2.2.0或者更高版本、Maven 3.0.4版本(或者最新3.0.x版本),其中,Hadoop 2.2.0只需采用最简单的方式安装即可,具体可参考我的这篇文章:Hadoop YARN安装部署,Maven安装方法很简单,可以在http://maven.apache.org/download.cgi上下载binary版本,解压后,配置MAVEN_HOME和PATH两个环境变量,具体可自行在网上查找相关方法,比如这篇“Linux下安装maven”,但需要注意,版本不是3.0.x版,Spark对版本要求很严格。
(2)硬件准备
Spark 2.2.0专门搞出来一个yarn-new支持hadoop 2.2.0,因为hadoop 2.2.0的API发生了不兼容变化,需要使用Maven单独编译并打包,而编译过程非常慢(一般机器,2个小时左右),且占用内存较多,因此,你需要一 台满足以下条件的机器作为编译机:
条件1:可以联网:第一次编译时,maven需要从网上下载大量的jar包,速度比较慢,如果你网络不行,建议直接放弃编译。
条件2:内存2GB以上
步骤2:下载编译spark 0.8.1或者更高版本
可以用git下载或者直接wget或者spark 0.8.1版本
wget https://github.com/apache/incubator-spark/archive/v0.8.1-incubating.zip
注意,0.8.1之前的版本不支持hadoop 2.2.0,从0.8.1版本开始支持。
下载之后,对其解压:
unzip v0.8.1-incubating
然后进入解压目录,输入以下命令:
cd incubator-spark-0.8.1-incubating
export MAVEN_OPTS=”-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m”
mvn -Dyarn.version=2.2.0 -Dhadoop.version=2.2.0 -Pnew-yarn -DskipTests package
一般需要等待很长时间,编译完成后,将spark内核打包成一个独立的jar包,命令如下:
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。