追溯近百年深挖大数据的发展历史,从1944年到2012年这期间大数据行业的发展历史,非常详尽。
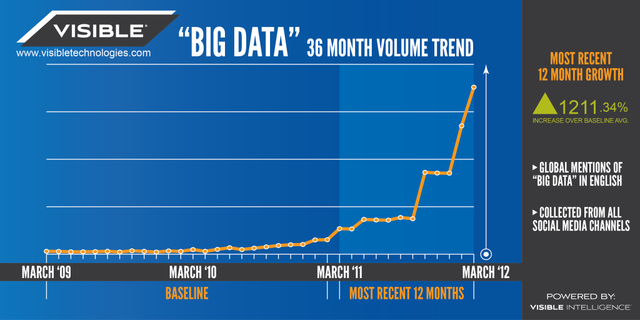
除了研究数据科学的一个非常短的历史之外,我还一直在研究数据如何变大的历史。在这里,我将重点放在量化数据量增长速度或普遍被称为“信息爆炸”的历史上(根据OED,该术语在1941年首次使用)。以下是数据量大小加上其他“第一”的历史上的主要里程碑,或与“大数据”思想演进有关的观察。
1944年弗雷蒙特骑士,卫斯理大学图书馆馆长,出版研究图书馆的学者和未来。他估计美国大学图书馆的规模每十六年翻一番。鉴于这一增长速度,Rider推测,2040年耶鲁图书馆将拥有“约2亿册”,将占用6,000多英里的货架... [要求]编目人员超过6000人。“
1961年Derek Price出版科学自从巴比伦以来,他通过观察科学期刊和论文数量的增长来绘制科学知识的增长。他的结论是,新的期刊数量呈指数增长而不是线性增长,每十五年翻一番,每半个世纪增加十倍。价格称之为“指数增长法”,解释说“每个[科学]进步以合理恒定的出生率产生新的一系列进步,使得出生次数与发现人口的大小成正比任何给定的时间“。
1964年4月,“电子计算机学报”(IEEE Transactions on Electronic Computers)中,Harry J. Gray和Henry Ruston发表了“应对信息爆炸的技术”,其中提出以下建议:
为了应对现在的信息爆炸,我们建议如下:1)没有人应该发表任何新的论文。 2)如果1)不可行,则只能出版短文。 “短”表示不超过2500个字符,以“空格”,标点符号等为字符。 3)如果采用2),应适用以下限制:“只有那些可以删除一个或多个现有文件的文件,删除一个或多个现有文件,其总长度为2501个字符以上。
上述建议做法的一个重要的副产品是减少甄选委员会的负担。这将发生,因为该人的出版物列表将被一个负数代替,表示他从当前信息存储中删除的网页数量。
1967年11月,BA Marron和PAD de Maine发布了ACM通信中的“自动数据压缩”,指出“近年来注意到的”信息爆炸“使得将所有信息的存储要求保持在最低限度。论文描述了“全自动,快速的三部分压缩机,可以与”任何“信息体系一起使用,以大大减少外部存储的需求,并提高通过计算机传输信息的速度。
1971年,亚瑟·米勒(Arthur Miller)在“隐私攻击”中写道:“很多信息处理程序似乎是通过他的档案将占用的存储容量的数量来衡量一个人。
1975年日本邮电部开始进行信息流通普查,跟踪日本传播的信息量(这个想法在1969年的文章中首次提出)。人口普查将“量词”作为统一的所有媒体测量单位。 1975年的人口普查已经发现,信息提供的增长速度比信息消费要快得多,而在1978年,它报告说,“大众媒体提供的单向通信信息的需求已经停滞不前,个人信息需求以双向通信为特征的电讯传媒业已大大增加。我们的社会正在迈向一个新的阶段,其中更加重视分段,更详细的信息来满足个人需求,而不是传统的大众传播信息。“[Alistair D. Duff 2000;参见Martin Hilbert 2012]
1980年4月在第四届IEEE海量存储系统研讨会上,Tjomsland发表了题为“从哪里走到哪里?”的讲话,他说:“很久以前与存储设备相关的那些意识到帕金森第一定律可能被改写为描述我们的行业 - 数据扩展以填补可用的空间。我相信大量数据被保留,因为用户无法识别过时的数据;存储过时数据的处罚与废弃潜在有用数据的处罚相比不太明显。“
1981年匈牙利中央统计局启动了一个研究项目,以说明该国的信息产业,其中包括测量信息量。研究至今仍在继续。 1993年,匈牙利中央统计局首席科学家伊斯特万·迪内斯(Istvan Dienes)汇编了国家信息帐户标准制度手册。 [见Istvan Dienes 1994和Martin Hilbert 2012]
1983年8月Ithiel de Sola Pool发表了“跟踪信息流动”的科学。从1960年到1977年的17个主要传播媒体的增长趋势来看,他得出结论,“通过这些媒体向美国人(10岁以上)提供的话语以每年8.9%的速度增长...实际上来自这些媒体的话每年只增长2.9%...在观察期间,信息流动的大部分增长是由于广播的增长...但是在这段时间结束时,[1977]情况正在改变:点对点媒体的增长速度高于广播。 “池,Inose,高崎和Hurwitz在1984年跟随通信流程:美国和日本的人口普查,这本书比较了美国和日本生产的信息量。
1986年7月,哈尔·贝克尔(Hal B. Becker)发表“用户真的可以按照今天的价格吸收数据吗?明天?“在数据通信。贝克尔估计,“古腾堡实现的重新编码密度约为每立方英尺500个符号(字符) - [4,000B.C.的密度的500倍]。苏美尔]粘土片。到2000年,半导体随机存取存储器应存储每立方英寸1.25X10 ^ 11字节。
根据R.J.T.数字存储对于存储数据而言比对纸张更具成本效益。 Morris和B.J.Truskowski在“存储系统的演进”中,IBM Systems Journal,2003年7月1日。
1997年10月,迈克尔·考克斯(David Cox)和戴维·埃尔斯沃斯(David Ellsworth)在IEEE第八届可视化会议论文集上发表了“应用程序控制的用于无核心可视化的需求寻呼”。他们以“Visualization为计算机系统提供了一个有趣的挑战”来开始撰写文章:数据集通常相当大,对主内存,本地磁盘甚至远程磁盘的容量进行了评估。我们称之为大数据的问题。当数据集不适合主内存(核心),或甚至不适合本地磁盘时,最常见的解决方案是获取更多的资源。“这是ACM数字图书馆中使用术语的第一篇文章“大数据。”
1997年,迈克尔·莱斯克(Michael Lesk)发表了“世界上有多少信息?”Lesk总结说:“可能有几千亿字节的信息被告知;磁带和磁盘的生产将在2000年达到这个水平。所以在短短的几年中,(a)我们将能够保存所有的东西 - 没有信息将被抛弃,(b)人们永远不会看到典型的信息。“
1998年10月K.G.科夫曼和安德鲁·奥利兹科发表了“因特网的规模和增长率”,他们得出结论:“公共互联网上的流量增长率低于往常被引用的比例,每年仍然在100%左右,远远高于流量在其他网络上。因此,如果目前的增长趋势继续下去,美国的数据流量将在2002年以前超过语音流量,并将由互联网主导。“Odlyzko后来成立了明尼苏达互联网流量研究(MINTS),跟踪了2002年互联网流量的增长到2009年。
1999年8月,史蒂夫·布莱森,David Kenwright,Michael Cox,David Ellsworth和Robert Haimes在ACM通讯中发表“实时浏览千兆字节数据集”。它是第一个使用术语“大数据”的CACM文章(文章部分之一的标题是“科学可视化的大数据”)。该文章的内容如下:“非常强大的计算机是许多领域的祝福。他们也是诅咒;快速计算排除了大量的数据。其中兆字节数据集曾经被认为是大的,我们现在可以从300GB范围内的各个模拟中找到数据集。但是,了解高端计算所产生的数据是一项重大的工作。正如不止一个科学家所说的那样,只要看看所有的数字就很难。数学家和先驱计算机科学家理查德·汉明(Richard W. Hamming)指出,计算的目的是洞察力,而不是数字。“
10月份,IEEE 1999年可视化会议上,Bryson,Kenwright和Haimes参加了David Banks,Robert van Liere和Sam Uselton的题为“自动化或互动:最适合大数据”的小组。
2000年10月,加州大学伯克利分校的Peter Lyman和Hal R. Varian发表了“多少信息?”这是第一个综合研究,以计算机存储的方式量化世界上创造的新的和原始的信息(不包括副本)的总量每年存储在四种物理媒体:纸张,电影,光学(CD和DVD)和磁性。研究发现,1999年,世界各地生产了大约1.5亿字节的独特信息,每个男人,女人和孩子约有250兆字节。它还发现“个人创造和存储大量独特的信息”(即所谓的“数据民主化”),“不仅数字信息的生产总量最大,而且也是增长最快的“称这个发现是数字化的主导地位,”莱曼和瓦里安声称,即使在今天,绝大多数的文字信息是“数字化的”,几年之内,这也是真实的图像。“ 2003年,世界在2002年产生了约5亿字节的新信息,92%的新信息存储在磁性媒体上,主要是在硬盘上。
2001年2月,Meta集团分析师Doug Laney发表题为“3D数据管理:控制数据量,速度和品种”的研究报告。十年后,“3V”已经成为普遍接受的三个定义维度大数据。
2005年9月,蒂姆·奥雷利(Tim O'Reilly)发布了“什么是Web 2.0”,他声称“数据是下一个英特尔内部”。O'Reilly:“正如Hal Varian去年在个人对话中所说的那样,SQL是新的HTML。 “数据库管理是Web 2.0公司的核心竞争力,所以我们有时把这些应用称为”信息“而不仅仅是软件。”
2007年3月,John F. Gantz,David Reinsel和IDC的其他研究人员发布了一篇名为“扩大数字宇宙:2010年全球信息增长预测”的白皮书。这是第一个估计和预测数字数据创建量的研究并每年复制。 IDC估计,2006年,世界创造了161亿字节的数据和预测,在2006年至2010年期间,每年向数字宇宙增加的信息将增加6倍至988埃,即每18个月翻一番。根据同一研究的2010年和2011年版本,每年创建的数字数据量超过了这一预测,到2010年达到1200亿字节,2011年增长到1800亿字节。
2008年1月,Bret Swanson和George Gilder发表了“估计Exaflood”,其中他们预测,到2015年,美国IP流量可能达到一个zettabyte,而2015年的美国互联网将比2006年上升至少50倍。
2008年6月思科发布了“思科视觉网络指数 - 2007 - 2012年预测与方法论”,这是“跟踪和预测可视化网络应用程序影响的持续举措”的一部分。它预测,“IP流量将几乎每两年翻一番到2012年“,2012年将达到半个zettabyte。由于思科的最新报告(2012年5月30日)估计2012年IP传输量将超过半数的千兆字节,所以预测持续良好,并注意到”过去已经增长了8倍5年。”
更新(通过Steve Lohr):2008年12月Randal E. Bryant,Randy H. Katz和Edward D. Lazowska发表了“大数据计算:在商业,科学和社会中创造革命性突破”,他们写道:“就像搜索引擎改变了我们如何访问信息,其他形式的大数据计算可以并将会改变公司,科学研究人员,医疗从业人员和我们国家的国防和情报操作的活动。大数据计算可能是过去十年来最大的计算创新。我们才开始看到其收集,组织和处理各行各业数据的潜力。联邦政府的适度投资可以大大加快其发展和部署。“
2009年12月Roger E. Bohn和James E. Short发表了“多少信息? 2009年美国消费者报告“。研究发现,2008年,”美国人消费信息约1.3万亿小时,平均每天接近12小时。消费总计3.6千字节和10,845万亿字,平均每天平均为100,500字,平均为34千兆字节。“Bohn,Short和Chattanya Baru在2011年1月跟随”多少信息? 2010年度企业服务器信息报告“,其中估计2008年,”全球服务器处理了9.57千兆字节的信息,接近10到22的功率,或1000万千兆字节。这是平均每个工人每天12吉字节的信息,每个工人每年约3 TB的信息。世界各地的公司每年平均处理了63 TB的信息。“
2010年2月,肯尼思·库奇(Kenneth Cukier)发表了“经济学人”中管理信息“数据,数据无处不在”的特别报告。写Cukier:“...这个世界包含了一个无法想象的大量的数字信息,它越来越快地越来越多...从无到有,从商业到科学,从政府到艺术的影响。科学家和计算机工程师为这个现象创造了一个新的术语:“大数据”。“
Martin Hilbert和Priscila Lopez发表了“世界科技存储,沟通和计算信息技术能力”。他们估计,1986年至2007年间,世界信息存储容量每年以25%的年复合增长率增长。他们还估计,1986年,99.2%的存储容量是模拟量的,但是2007年存储容量的94%是数字化,完全扭转角色(2002年,数字信息存储首次超越非数字化)。
2011年5月麦肯锡全球研究院的James Manyika,Michael Chui,Brad Brown,Jacques Bughin,Richard Dobbs,Charles Roxburgh和Angela Hung Byers发表了“大数据:创新,竞争和生产力的下一个前沿”,他们估计“到2009年,几乎所有美国经济部门的平均每个拥有1000多名员工的公司的存储数据(占美国零售商沃尔玛1999年数据仓库的两倍),证券和投资服务业领先于每个企业的存储数据。总的来说,该研究估计,企业存储的7.4亿字节的新数据和消费者2010年的存储量为6.8亿字节。
2012年4月国际通讯杂志发布了一篇题为“信息容量”的专题小组,介绍了衡量信息量的各种研究的方法和结果。在“跟踪信息流入家庭”中,Neuman,Park和Panek(按照日本MPT和Pool以上使用的方法)估计,美国家庭的媒体供应总量从1960年的每天大约50,000分钟上升到1960年的在2005年接近90万。而从2005年的供需比率来看,他们估计美国人正在“每分钟可以消费的接近一千分钟的调解内容”。在“国际生产和传播信息,“Bounie和吉尔(以下Lyman和Varian以上)估计,2008年世界产生了14.7亿字节的新信息,2003年几乎是信息量的三倍。
注意:我故意省略了对信息的价值(和成本)的讨论,并试图以资金和/或信息/知识工作者(例如Machlup,Porat,Schement)的数量来衡量信息经济。 还有一些关于“信息超载”或类似术语的许多有趣的引用,最近詹姆斯·格莱克(James Gleick)已经在“信息”中进行了调查(具体见第15章)。 格列克还在克劳德·香农(Claude Shannon)的笔记中发现,香农试图估计(1949年)各种项目的“位存储能力”,如打孔卡,“人类的遗传构成”(根据Gleick,第一次,“ 任何人都建议基因组是一个信息存储可测量的位“)和留声机记录。 香农名单上最大的项目是100万亿,是国会图书馆。
原文地址:https://whatsthebigdata.com/2012/06/06/a-very-short-history-of-big-data/
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。


































