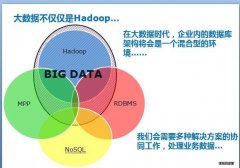
Hadoop将无法独自处理大数据Sriram说,“Hadoop和MapReduce模式绝对是解决大数据问题的方式之一。但你需要记住的是,按照目前的情况来看,Hadoop仅仅是对于批处理来说比较好。相信很快,我们同时需要能够实时处理这些数据。&r
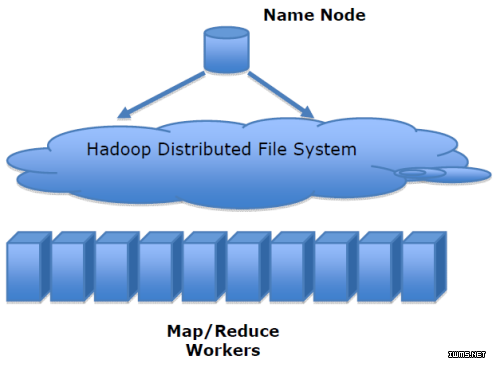
Hadoop将无法独自处理大数据
Sriram说,“Hadoop和MapReduce模式绝对是解决大数据问题的方式之一。但你需要记住的是,按照目前的情况来看,Hadoop仅仅是对于批处理来说比较好。相信很快,我们同时需要能够实时处理这些数据。”作为一名Hadoop顾问的Sriram并不是说这种无处不在的平台速度缓慢。使用这样一个强大的框架,大量数据可能在一分钟之内就处理完,但是那并不总是足够好。如何解决这个问题呢?
Hortonworks公司战略副总裁Shaun Connolly指出, Hadoop一直不断的变得更快更灵活。 “我们现在越来越明确的要求优化Hadoop使用的NoSQL数据库。它可以利用内存处理,这样请求就能更快的返回,而不使用批量处理。如果使用YARN,你其实可以基于内存做更多的交互式查询。”除此之外,还有一个热潮兴起的流式分析工具或过程依赖于像Storm这样的技术,开发人员就可以使用YARN这样的架构嵌入到Hadoop里面去。如今使用Hadoop的大数据用户都在研究近实时性能。然而,这并不是100%的实时,一个重要的区别在于,当组织使用计算机来做瞬间快速决定的时候,必须参照很久以前的分析报告,而这些可能已经被人为破坏。
这个时候LAMBDA架构就有了用武之地。它允许企业组织从他们大量数据中分离出增量数据进行单独处理。大部分的数据都进入到批处理系统中,而一个叫做“速度层”的对数据进行实时处理。NoSQL数据库(他们中的大部分)都有自己的生态系统,因为它们提供了专门的工具来管理数据,以适应特定案例。
整合将至关重要,但没有一个工具对大家都有效
说到向Hadoop提供援助之手,精心设计的工具正在以惊人的速度在大数据空降急剧增加。 ElasticSearch,Pentaho,以及许多其他工具覆盖了整个大数据生态系统不同细分市场。但下一个重要阶段是如何让他们能够更好的协同工作。直到这个阶段的到来,大数据的管理还将比较随意。
当然,这并不意味着一个集成产品将永远适合所有的商业模式。数据以多种形式出现,并且每个企业组织都希望利用这些信息做不同的事情。企业组织将需要使用各种不同的方式来处理他们的数据,根据数据的来源,格式,他们为什么收集,他们希望如何存储,他们想如何分析,还有他们需要以多快的速度来处理。我们希望在整合的同时仍然保持模块化。这将允许企业为自己独有的使用案例创建合适的工具时无需每次都重新开发。
熟悉大数据技术的软件工程师将会有很大的需求
Mohan指出,在大数据空间最显着的挑战之一,应该是与微乎其微的人才库相关。“拥有这方面经验的人才数量并不多。”这并不意味着软件工程师需要去上学并获得博士学位。技术工人并不需要一个博士学位来理解大数据。然而,他们确实需要掌握知识和专业技能。Sriram说,这个目标是任何一个愿意投入时间和精力的软件工程师都可以实现的。课堂上不一定是唯一的起点。经历努力实现关系型数据库规模并且过渡到非关系型数据库,让其都为掌握大数据问题奠定坚实的基础。
Mohan博士正在做的是,为当今的软件工程师准备未来的工作世界。他将在波士顿的Big Data TechCon提供两个教育机会:Hadoop的数据传输工具和MapReduce介绍。对于那些想要在未来几年成为就业市场高需求人才的人,现在就是开始时间。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。