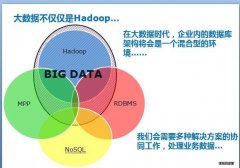
Cloudera将Hadoop作为企业数据枢纽的想法非常大胆,但是现实却大相径庭。Hadoop距离让其他大数据解决方案黯然失色还有很长的一段路要走。当你有了一把足够大的锤子时,所有的东西看起来都是钉子。这是Hadoop 2.0所面临的众多潜在问题之一。目前
Cloudera将Hadoop作为企业数据枢纽的想法非常大胆,但是现实却大相径庭。Hadoop距离让其他大数据解决方案黯然失色还有很长的一段路要走。
当你有了一把足够大的锤子时,所有的东西看起来都是钉子。这是Hadoop 2.0所面临的众多潜在问题之一。目前,让开发者和终端用户最关注的是Hadoop 2.0大规模地修改了大数据处理的框架。Cloudera计划将Hadoop 2.0打造成一把能够应对所有不同钉子的万能锤子。
毫无疑问,Hadoop 2.0与之前的产品相比性能有了很大的提升。之前对于MapReduce任务,Hadoop只是一个批量数据处理框架。如今Hadoop 2.0成为了一个可在跨节点系统中部署应用的通用框架,MapReduce也能够跨节点运行,这一功能显然让Cloudera感到非常兴奋。在2013年10月底于纽约召开的O'Reilly Strata-Hadoop大会的主题演讲,Cloudera向与会者阐述了由Hadoop驱动的“企业数据枢纽”理念。 各种形式的数据都可输入这个枢纽中,数据在这里可被恰当处理,并被按需提取。
这听起来非常不错,但是有多大的可行性呢?对于那些没有及时涉足大数据,现在才开始为海量数据农场(data farms)寻找恰当位置的企业来说,这类枢纽距离他们太遥远了。将这些“数据孤岛”纳入到Hadoop设施中并不是件容易的事。
尽管Hadoop也是一个相当大的障碍,但是这一理念最大的障碍并不是Hadoop本身。通过在Strata-Hadoop大会上与厂商和用户交流,我们发现,厂商和用户只是将Hadoop视为一堆水桶的零件而已,它们还需要被焊接起来才能充分地发挥作用。
Hadoop的大多数功能正在通过第三方实现。这些第三方将Hadoop的功能引入到了即时部署型(ready-to-deploy)的产品当中,不仅仅是Cloudera或Cloudera的对手Hortonworks,还包括微软(Hortonworks的合作伙伴)、亚马逊、SoftLayer、Rackspace等云服务提供商。他们当中只有一小部分还没有提供软件工具所需要的各种程度的抽象化。Puppet或Python脚本在这里只是选项,不是必需的。
即便在小规模的部署当中,Hadoop活动部件和尖锐毛边的绝对数量也非常的吓人。在小组会议上,甲骨文产品经理Dan McClary介绍了甲骨文在创建Hadoop工具时所付出的艰辛。这让我们看到了将Hadoop整合到可交付产品中需要付出多少努力,即便是对于甲骨文这样的大公司来说也并不容易。McClary表示,随着时间的推移,Hadoop的毛边和未完善之处将在社区和厂商的共同努力下被磨平和解决,但是这个时间肯定不会马上到来。
另一个主要障碍仍然是将应用迁移到Hadoop。基于Hadoop的新基础设施YARN(Yet Another Resource Negotiator,另一种资源协调者)比以往更具开放性,但要想在上面运行应用必须重新编写应用,这一工作并不轻松。届时可能会有一些应急性设备出现,以加快这一进程。例如,可以将应用随意加入框架内的某种虚拟化封装工具,不过这一工作也不轻松。
目前业内正在做大量工作,例如开发连接器、数据漏斗等,以便让Hadoop更好地与现有应用协同工作。尽管大部分人都认为现有应用最终都将迁移至Hadoop上,但是几乎很少有研讨会把重点放在将现有应用向Hadoop迁移这一问题上。与废弃现有应用一切重新开始相比,大多数人还是希望将现有应用迁移至Hadoop。
也就是说,O'Reilly会议上活跃程度是这种情况多久才会发生的重要预兆。到2014年这时候,这一会议将在纽约曼哈顿贾维茨会议中心召开,届时Cloudera的部分声明可能并不会引起太多的乐观情绪。目前的趋势是朝着将Hadoop作为现有大数据系统的补充这一方向发展的,而不是向着将Hadoop作为现有大数据系统的升级系统发展的。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。