数据的分析是大数据处理的核心。传统数据分析主要是针对结构化数据,其大致过程为:首先利用数据库存储结构化数据,在此基础上构建数据仓库,根据需要再构建相应立方体并进行联机分析处理。这一过程在处理相对较少的结构化数据时非常高效。但对于大数据而言,
数据的分析是大数据处理的核心。传统数据分析主要是针对结构化数据,其大致过程为:首先利用数据库存储结构化数据,在此基础上构建数据仓库,根据需要再构建相应立方体并进行联机分析处理。这一过程在处理相对较少的结构化数据时非常高效。但对于大数据而言,分析技术面临3 个直观问题:大容量数据、多格式数据及分析速度,这使得标准存储技术无法对大数据进行存储,从而需要引进更加合理的分析平台进行大数据分析。目前,开源的Hadoop 是广泛应用的大数据处理技术,它也是分析处理大数据的核心技术。
Hadoop是一个基于Java的分布式密集数据处理和数据分析的软件框架,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力高速运算和存储。其基本工作原理为:将规模巨大的数据分解成较小、易访问的批量数据并分发到多台服务器来分析。主要包括文件系统(HDFS)、数据处理(MapReduce)两部分功能模块,最底层是HDFS 用来存储Hadoop 集群中所有存储节点上的文件,HDFS 上一层是MapReduce 引擎,该引擎由Job Trackers 和Task Trackers 组成。其组成架构如图所示:
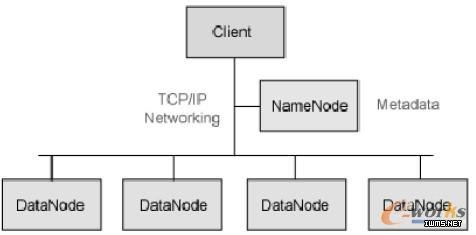
图 Hadoop组成架构图
鉴于商用的硬件集群上。所谓商用硬件并非低端硬件,其故障率比低端硬件要低很多。Hadoop 不需要运行在价格昂贵并且高度可靠的硬件上,即使对于节点故障的几率较高的庞大集群,HDFS在遇到故障时仍能够继续运行且不让用户察觉到明显的中断,这种设计降低了对机器的维护成本,尤其是在用户管理上百台甚至上千台机器时。
Hadoop 的设计是基于一次写入、多次读取的高效访问模式。每次对数据的分析会涉及到数据所在的整个数据集,这种高数据的吞吐量会造成高的时间延迟,对于低延迟的数据访问,HBase是更好的选择。HDFS 采用master/slave 的构架,即一个HDFS集群由一个NameNode(master)和多个DataNode(slave)组成。NameNode 是一个中心服务器,负责管理HDFS 的命名空间,并维护HDFS 的所有文件及目录。这些信息以命名空间镜像文件和编辑日志文件的形式永久地保存在本地磁盘上。它还记录着每个文件中各个块所在的DataNode 信息,但不永久保存块的位置信息,因为DataNode 会在系统启动时重新建立新的位置信息。同时,NameCode 还负责控制外部Client 的访问。
DataNode 是HDFS 的工作节点,在集群中一般为一个机器节点一个,负责管理节点上附带的存储。它们根据客户端需要或NameNode 调度存储并检索数据块(Block),执行创建、删除和复制数据块的命令,并定期向NameNode 发送存储数据块列表的动态信息,NameNode 获取每个DataNode 的动态信息并据此验证块映射和文件系统元数据。
3.2 MapReduce
MapReduce是用于处理大数据的软件框架。其核心设计思想为:将问题分块处理,把计算推到数据而非把数据推向计算。最简单的MapReduce应用程序至少包含3 个部分:Map函数、Reduce 函数和main函数,其模型相对简单,将用户的原始数据进行分块,然后交给不同的Map任务区执行Map函数处理输出中间结果,Reduce函数读取数据列表并对数据进行排序并输出最终结果。其流程如图所示:
3.3 Hadoop 的优势及问题
Hadoop 是一个能够对大量数据进行分布式处理的软件框架,同时是以一种可靠、高效、可伸缩的方式进行处理。可靠是因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理;高效是因为它以并行的方式工作,通过并行处理加快处理速度;可伸缩是说它能够处理PB 级数据。
但与其他新兴科技一样,Hadoop 同样面临一些需要解决的问题。(1)目前Hadoop 缺乏企业级的数据保护功能,开发人员必须手动设置HDFS 的数据复制参数, 而依赖开发人员来确定复制参数很可能会导致对存储空间的浪费。(2)Hadoop 需要投资建设专用的计算集群,但这通常会产生独立存储、计算资源以及存储或CPU 资源利用问题,且这种存储在与其他程序的共享问题中也存在兼容性问题。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。