上海宝信高级工程师汪振平从金融行业入手,从背景、需求与目标、问题、系统架构及其它Hadoop相关知识5个方面对基于Hadoop的日志交易平台进行深度分享:背景使用场景:信用卡消费的延时、交易失败和失败的原因及类型、不规范交易机构和商户的寻找与产生原因。
背景
使用场景:信用卡消费的延时、交易失败和失败的原因及类型、不规范交易机构和商户的寻找与产生原因。
数据特征:在数据量上,每天近3亿笔交易日志;在数据状态上,目前仅存储拟合后的交易,对原始交易日志不可用。
需求与目标:交易日志的秒级查询、交易失败分析、不合规交易分析、用户自助分析、与其它数据结合,找出交易失败原因及分析报告、报表。
打造的挑战:如何获取日志对生产系统影响最小、如何快速将每天3亿+条交易日志转译并存储到Hadoop集群、大量的作业如何管理及如何实现秒级查询。
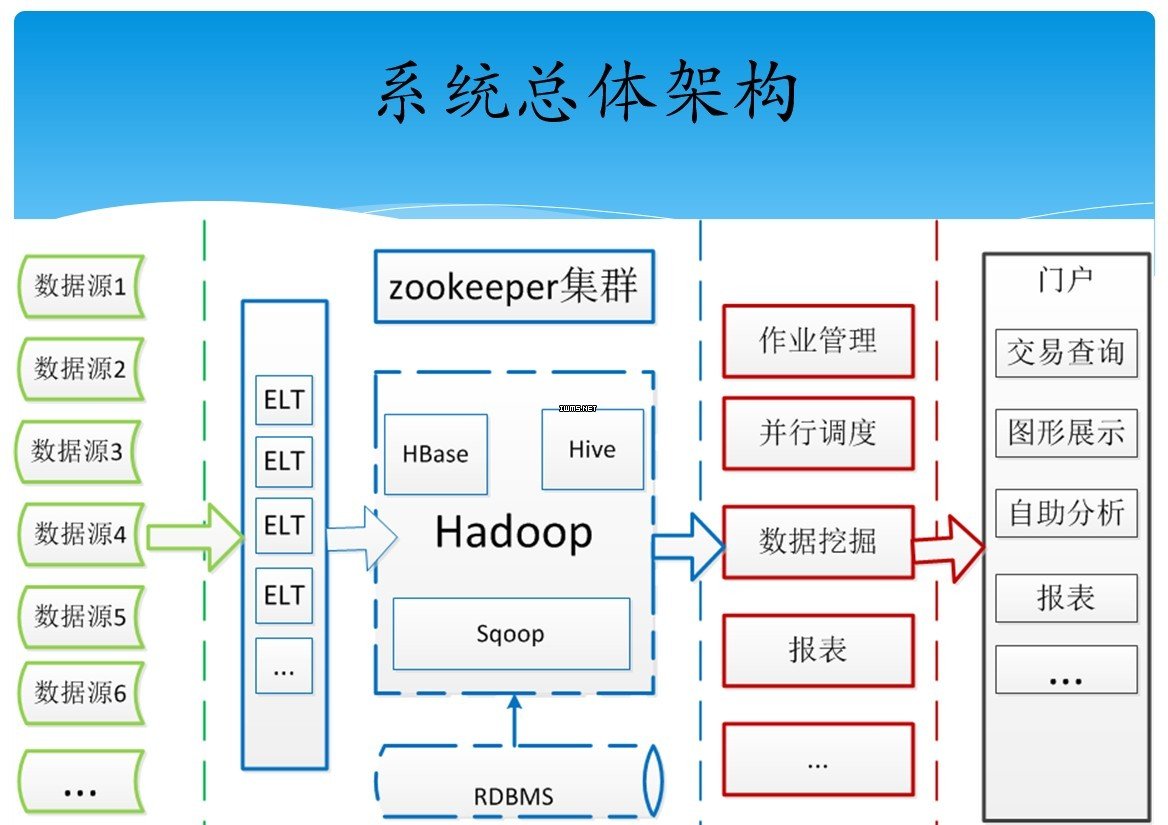
系统的打造及架构
系统的打造就是一个发现问题和解决问题的过程,基于需求和背景,对问题逐个击破,汪振平分享了他的宝贵经验:
1. 将数据收集影响降到最低:总体上讲,无非就是基于业务选择合适的时间点和方式,这里的实际情况是:每天上午1:00~5:00之间,由于数据以二进制方式存储在本地文件中,且涉及多台机器,同时也为了能快速获取数据,采用了客户端与同业务数据源一一对应关系,每个客户端可以依据配置,能同时获取不同业务系统数据。
2. 快速将3亿+条交易日志转译并存储到hadoop集群
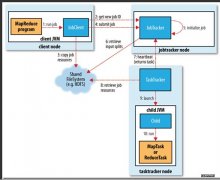
在这里汪振平弃用了MapReduce,选择了自主研发主要是因为:HDFS对文件进行切割分布,而文件又是以2进制形式进行存储。基于文件切割、报文之间分界、不完整报文等因素,而且对日志在解析过程中可用性不可控,同时也由于日志解析规范的复杂性决定。
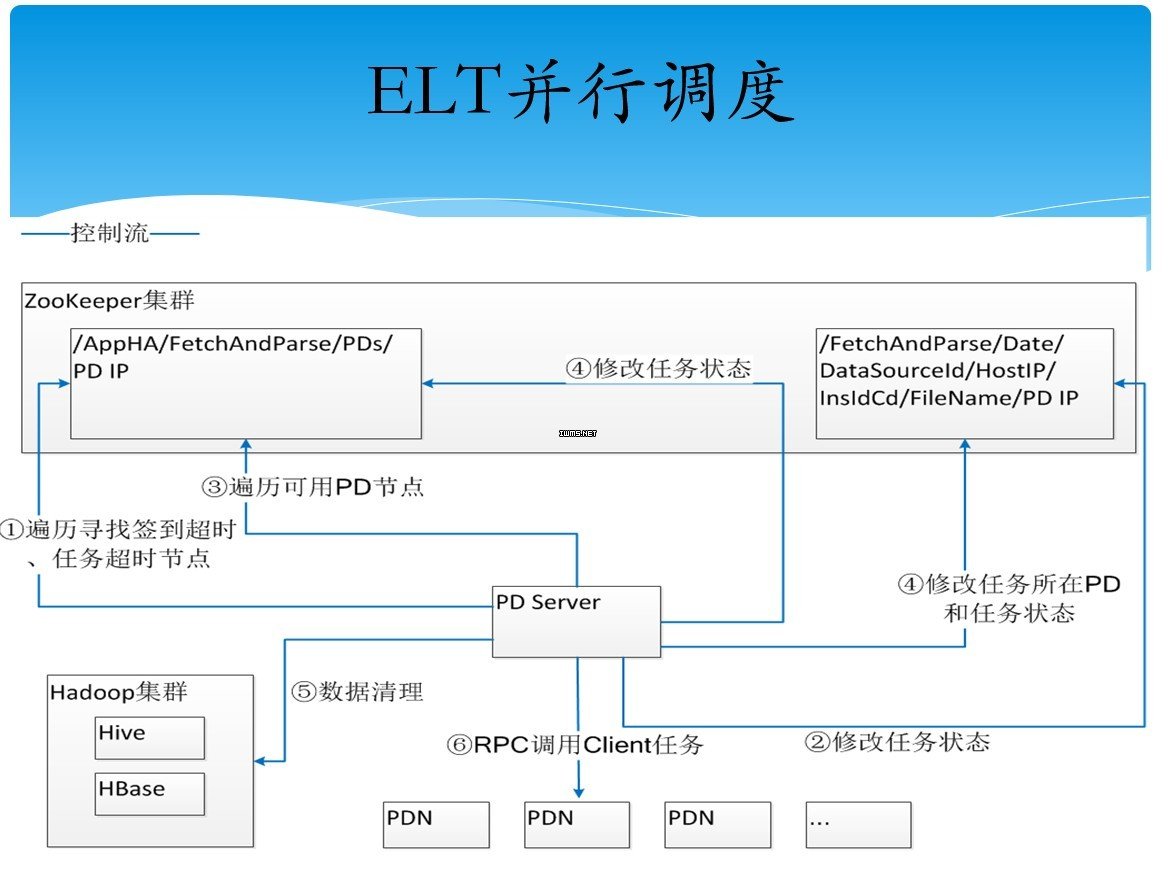
3. 大量作业的管理
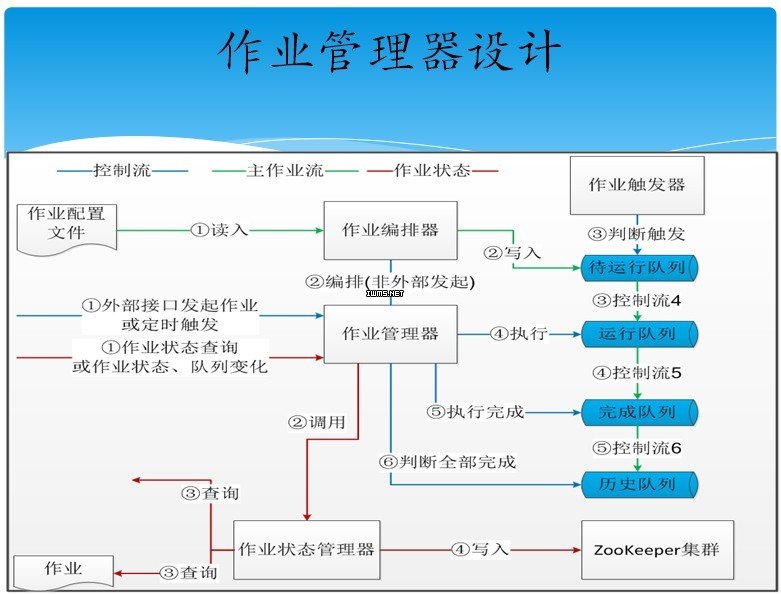
上图为其公司内部的作业管理架构,主要涉及到4个组件:作业编排器,主要负责编排作业;作业管理器,主要负责作业调度;作业状态管理器,用于审计并发现问题所在;作业触发器,触发作业,触发依赖性作业或者是其它作业。
秒级查询:汪振平通过Hbase存储、二级索引、ParallelRegionQuery、支持数据区间查询、针对HBase访问API封装,提高开发效率及对集群调优实现了妙级的查询。
最后汪振平还分享了上海宝信的集群状态、Hadoop相关知识以及Hadoop个人的使用及学习相关经验,在使用经验上他认为初期要做好规模、网络、服务器硬件配置运行环境等的规划,而使用过程中则要注重集群的监控、运行日志的收集和分析及操作系统的共同调优,其中应急流程更是必不可少的一环。而在学习方面,他认为多读源码、深入了解系统运行原理是非常必要的,但无需在早期进行代码修改。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。