在国内银行业尚无Hadoop技术成型案例的情况下,光大银行首个基于Hadoop技术的应用试点项目——历史数据查询项目于2013年10月底成功投产上线,这是Hadoop技术在银行系统应用上的一个重要里程碑。从硅谷到北京,从中关村到金融
在国内银行业尚无Hadoop技术成型案例的情况下,光大银行首个基于Hadoop技术的应用试点项目——历史数据查询项目于2013年10月底成功投产上线,这是Hadoop技术在银行系统应用上的一个重要里程碑。
从硅谷到北京,从中关村到金融街,大数据的话题越来越热门,关于大数据技术的探索越来越广泛。致力于打造最具创新力银行的中国光大银行紧密跟踪业务、技术发展趋势,开展了对大数据技术的深入研讨,并尝试将大数据领域的Hadoop技术应用于银行IT系统建设。光大银行首个基于Hadoop技术的应用试点项目——历史数据查询项目于2013年10月底成功投产上线,这是Hadoop技术在银行系统应用上的一个重要里程碑。本文将浅析光大银行历史数据线上化研究和Hadoop技术应用。
一、历史数据线上化带给系统的需求
中国光大银行的客户历史交易数据原本存放在磁带库和光盘库中,查询的效率较低、工作量较大。将这些历史数据放入联机服务系统,提供即时高效的查询服务,既是提升客户服务的迫切要求,也是盘活数据资产、发挥数据价值的重要基础。
从业务需求角度看,这个系统需要提供历史交易数据的导入和查询服务,具有对数据一次写入多次读取的功能特性;从系统功能上看,该系统需要具备存储光大银行10余年历史交易明细数据的能力,并依托于历史积存的大数据,支持大时间跨度的高性能查询,实现线下数据线上化的目标;从系统运维角度看,该系统需要具有可持续发展的能力,满足未来增量交易数据的持续沉淀以及数据规模外延的扩大,具备较好的可扩展性。可以看出,虽然这个系统的业务功能并不复杂,但对系统的技术要求很高。
二、选择Hadoop技术
光大银行在项目技术选型期间,首先考虑了利用传统技术的可能性。采用传统技术,优点在于具备充沛的成型案例,相对承担较小的风险。然而传统存储技术对于硬件设备要求较高,成本昂贵。同时,响应效率随着存储数据量和查询数据量的增长而降低;在扩展性方面具有较大局限性。
限于传统技术所带来的诸多问题,在科技飞速发展的时代,是否有更适合本项目特点的新技术?答案是肯定的。
Hadoop技术,在大数据时代应运而生,已经在互联网行业广泛应用,依靠分布式架构实现大数据存储和大数据运算,具有低硬件成本、高性能、高可用性、高可扩展性的特点,尤其适用于对数据一次写入多次读取。这些特点正是历史数据线上化的要求。然而,该技术在国内银行尚无成型案例,是否适合银行运营体系,是否能满足银行系统对稳定性、安全性的要求还有待考察。
以“打造国内最具创新能力的银行”为愿景的光大银行,持续保持着对各项新业务、新技术发展趋势的跟踪,光大科技人对于在互联网领域应用广泛的Hadoop技术也进行了充分预研。在历史数据查询项目中,Hadoop的解决方案以其低成本、易扩展、高可靠的特点在各项方案中脱颖而出。
三、Hadoop技术在项目中的应用
Hadoop,由HDFS、MapReduce、Hbase、Pig、Hive和ZooKeeper等成员组成,各成员都具有独特的功能和鲜明的特点。根据历史数据线上化的特点,本项目主要选择使用了HDFS、MapReduce、Hbase和ZooKeeper等成员。
下面介绍应用Hadoop技术方面的特点。
1.单集群VS双集群。为满足对系统灾备的要求,需要同时在生产机房和灾备机房部署集群,且当生产机房失效,灾备机房的集群可对外独立提供服务支持。
Hadoop技术的设计初衷是依靠集群力量高效工作,基于集群架构的优势,从理论上可以在多个机房部署同一大型集群。在两个机房部署单集群的方案虽然可以充分利用Hadoop技术的集群理念,但也会遇到一些问题:首先,需要保证单一机房数据完整性,使数据复本分布到不同的机房,以保证单边机房可以随时对外独立提供服务支持。其次,当出现非系统性突发状况时,很难保证持续稳定的服务供应,容易造成集群内管理的混乱。此外,DateNode间的数据传输是常态,会大量占用机房间的网络带宽资源。要解决上述问题,需要对Hadoop架构进行周密的重构,进行大规模的改造。
综合分析,结合项目背景,改进原有思路,采用双集群解决方案。在两个机房分别部署一个集群,集群间服务、数据独立。在单机房,单系统出现异常时,快速切换,保证数据安全性和业务连续性;双集群的数据独立传输、整合和加载,最大力度节约机房间的网络资源;双集群特有的双活设计,即两个集群同时提供查询服务,提高了硬件资源利用率。
2.高可用性。预防出现单点故障,保证系统运行,在HDFS采用双NameNode,在Hbase采用双Hmaster的设置,并由ZooKeeper进行管理,出现故障时的自动切换。
采用Hadoop技术对数据的多冗余复本机制,确保无单点故障。在数据节点的某一节点出现故障时,仍保证数据完整,可以提供服务,并且可以自动复制数据,保证达到设置的复本数量。
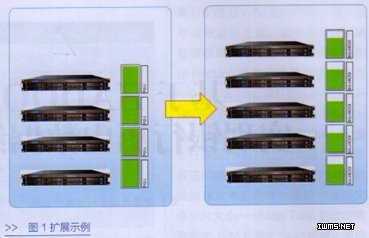
3.可扩展性。系统采用Hadoop架构,实现动态扩展,系统扩容,平台增加新节点后,自动在所有节点之间均衡数据。后台根据忙闲程度自动发起,占用少量系统资源,无需人工干预,实现数据均衡分布(如图所示)。
四、银行数据支持平台的创新
通过历史数据查询项目的实施,光大银行完成了历史数据线上化,提高了业务办理效率,提升了客户服务质量。本项目使银行对Hadoop技术的研讨付诸于实践,使Hadoop技术与银行运营体系深度结合,是对银行数据支持平台的一次勇敢创新。这项技术具有低成本、高可用、易扩展三大特点,有效解决了海量数据存储问题,突破计算能力瓶颈,大幅度节约投资,从而优化投资效率,提高投入产出比。此外,本项目在大数据存储、大数据查询、大数据运算等领域,对Hadoop技术的应用进行了有益的探索,为银行迎接“大数据”时代积累了宝贵经验。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。