
大数据新手入门hadoop的初步理解
大数据新手入门hadoop的初步理解:hadoop的初步理解 1:hadoop到底是什么呢? hadoop是一个解决方案,是一个能够处理大数据量的的分布式处理系统。...
大数据新手入门hadoop的初步理解:hadoop的初步理解 1:hadoop到底是什么呢? hadoop是一个解决方案,是一个能够处理大数据量的的分布式处理系统。...

以Hadoop Tutorial为主体带大家走一遍如何使用Hadoop分析数据!MapReduce框架由一个Jobracker(通常简称JT)和数个TaskTracker(TT)组成(在cdh4中如果使用了Jobtracker HA特性,则会有2个Jobtracer,其中只有一个为active,另一个作为standby处于inactive状态)。JobTr...
已经发布了早期代码,让客户可以将这个Java架构接入到SQL Server 2008 R2、SQL Server Parallel,微软目前已经开始提供Hadoop Connector for SQL Server Parallel Data Warehouse和Hadoop Connector for SQL Server社区技术预览版本的连接器。...

Nutch采用一个MR对爬取下来的文档进行清洗和封装成一个action列表。Nutch会将封装好的数据采用基于http的POST的方法发送一个请求数据包给solr的服务器,solr.commit();这个方法在前面一篇文章中解释有些偏差,solr的整个事务都是在solr服务器端的,这跟以前的的事务有所...

hadoop集群规划1.1 共有A、B、C 三台机器;1.2 A 作为master,B作为slave1,C作为slave2;1.3 IP A :192.168.1.103;B:192.168.1.104;C:192.168.1.101;1.创建 hadoop用户,并使该用户拥有root权限(在master机器上进行)...

Hadoop被公认是一套行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力(Gartner)。几乎所有主流厂商都围绕Hadoop开发工具、开源软件、商业化工具和技术服务。今年大型IT公司,如EMC、Microsoft、Intel、Teradata、Cisco都明显增加了Hadoop方面的投入。...

新的Hadoop不仅能够进一步刺激为Hadoop编写应用程序,同时也将在Hadoop内创造全新的数据处理方法,这在此前的架构限制下是根本不可能实现的。总之,这是好东西。Cloudera和Hortonworks都是Hadoop 2的坚实支持者,他们并没有转向其他技术或者坚持上一代技术,从这一点来...
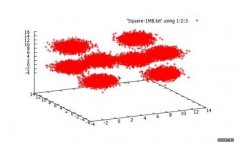
使用Kmeans数据的对比hadoop和spark。读取HDFS上的block到内存,每个block转化为RDD,里面包含vector。然后对RDD进行map操作,抽取每个vector(point)对应的类号,输出(K,V)为(class,(Point,1)),组成新的RDD。...

Spark所谓的简单其实说的大多是关于Hadoop中的Java API而不是Spark本身。即使是简单的例子在Hadoop中通常也会有大量的样板代码。但从概念上讲,Hadoop非常简单,它只提供了两种基本操作:并行的映射(Map)和规约(Reduce)操作。如果用相同的方式,对表示相似分布式集合,...
首先要下载mongo-Hadoop adaptergit clone https://github.com/mongodb/mongo-hadoop.gitgit checkout release-1.0然后进入mongo-hadoop目录,找到b...
在2014年4月7日,Apache发布了Hadoop 2.4.0 。相比于hadoop 2.3.0,这个版本有了一定的改进,突出的变化可以总结为下列几点(官方文档说明):1 支持HDFS访问控制列表(ACL,Access Control Lists)这...

2008年于中科院声学所获博士学位,主导了优酷土豆视频推荐支撑平台设计与开发,目前负责低延时、高并发的大数据应用支撑平台建设。从视频网站的分类来说,优酷土豆属于两者兼备的模式(用户产生内容+专业视频内容)。而这两种类型的网站内容和用户行为各异,相...

初学者运行MapReduce作业时,经常会遇到各种错误,由于缺乏经验,往往不知所云,一般直接将终端打印的错误贴到搜索引擎上查找,以借鉴前人的经 验。然而,对于hadoop而言,当遇到错误时,第一时间应是查看日志,日志里通产会有详细的错误原因提示,本文将总结...

个人汇总:hadoop :Hadoop是一个能够对大量数据进行分布式处理的软件框架,它是一种技术的实现大数据:资料:我们都听过这个预测:到2020年,电子数据存储量将在2009年的基础上增加44倍,达到35万亿GB。根据IDC数据显示,截止到2...

作者:chszs,转载需注明。博客主页:http://blog.csdn.net/chszs有人问我,“你在大数据和Hadoop方面有多少经验?”我告诉他们,我一直在使用Hadoop,但是我处理的数据集很少有大于几个TB的。他们...

先粗略说一下“hadoop fs”和“hadoop dfs”的区别:fs是各比较抽象的层面,在分布式环境中,fs就是dfs,但在本地环境中,fs是local file system,这个时候dfs不可用。1、列出...
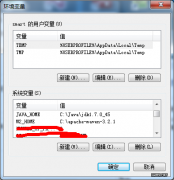
所需工具1.Windows 7 32 Bit OS(你懂的)2.Apache Hadoop 2.2.0-bin(hadoop-2.2.0.tar.gz)3.Apache Hadoop 2.2.0-src(hadoop-2.2.0-src.tar.gz)3.JD...

1.Hadoop集群可以运行的3个模式?单机(本地)模式伪分布式模式全分布式模式2. 单机(本地)模式中的注意点?在单机模式(standalone)中不会存在守护进程,所有东西都运行在一个JVM上。这里同样没有DFS,使用的是本地文件系统。...

首先在yarn-site.xml中,将配置参数yarn.resourcemanager.scheduler.class设置为org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairSch...
注意,配置这些参数前,应充分理解这几个参数的含义,以防止误配给集群带来的隐患。另外,这些参数均需要在yarn-site.xml中配置。1. ResourceManager相关配置参数(1) yarn.resourcemanager.address...

最近抛弃非ssh连接的Hadoop集群部署方式了,还是回到了用ssh key 验证的方式上了。这里面就有些麻烦,每台机器都要上传公钥。恰恰我又是个很懒的人,所以写几个小脚本完成,只要在一台机器上面就可以做公钥的分发了。首先是生成ssh key脚本#!/...

类型一: 一一对应file1:a 1b 2c 3file2:1 !2 @3 #file1和file2进行关联,想要的结果:a !b @3 #思路:1、标记不同输入文件2、将file1的key、value颠倒 ;file1和file2的key相同,file1的v...

Hello 大家好,我是stefan,今天来和大家分享下如何将Hadoop1.x迁移至Hadoop2.x。这篇博文提供了将Hadoop MapReduce应用从Hadoop1.x迁移到Hadoop2.x的方法。在2.x的版本中,apache将resource...

利用Mahout和Hadoop处理大规模数据规模问题在机器学习算法中有什么现实意义?让我们考虑你可能需要部署Mahout来解决的几个问题的大小。据粗略估计,Picasa三年前就拥有了5亿张照片。 这意味着每天有百万级的新照片需要处理。一张照片的分析本身...

本文主要讲对key的排序,主要利用Hadoop的机制进行排序。1、Partitionpartition作用是将map的结果分发到多个Reduce上。当然多个reduce才能体现分布式的优势。2、思路由于每个partition内部是有序的,所以只...