以DRAM性能为基准对DCPMM进行了基准测试,突出了优点和缺点。
去年4月,英特尔发布了其Optane数据中心永久性存储器模块(DCPMM)–字节可寻址的非易失性存储器–以增加主存储器容量并提供接近DRAM速度的性能。值得注意的是,尽管该技术目前仅与某些Intel处理器兼容,但它正在引起系统制造商的兴趣。上周,日本国立先进工业科学技术研究院(AIST)发表了一篇论文,以DRAM性能为基准对DCPMM进行了基准测试,突出了优点和缺点。
当然,Optane是英特尔 最初与美光科技联合开发的3D XPoint媒体的实现。广泛地说,3D XPoint试图填补快速但易失且密度较小的DRAM技术与成本较低的非易失性NAND闪存之间的功能差距。Optane使用无堆叠(3D)晶体管技术来节省空间并提高性能。
根据AIST的说法,它之所以进行了该项目,是因为到目前为止只有很少的关于DCPMM性能的报告。尽管与DRAM的性能差距很大,但相对于NAND的增益差距也是如此。这是论文结论的摘录:
“为了补充先前有关英特尔傲腾DCPMM的性能报告,我们使用自己的测量工具进行了实验。我们观察到随机只读访问的等待时间约为374 ns。涉及随机回写的访问时间为391 ns。交错存储模块的只读访问权限和涉及写回操作的带宽分别约为38 GB / s和3 GB / s。
“许多应用程序(例如,特别是大规模的HPC和AI工作负载)将从DCPMM扩展的大容量主存储器中受益。但是,DCPMM和DRAM之间的巨大性能差距为系统软件研究提出了新的挑战。我们目前正在使用应用程序进行实验,并将在以后的出版物中报告详细信息。” AIST的Takahiro Hirofuchi和Ryousei Takano写道。
下表和测试系统的说明提供了更清晰的比较。
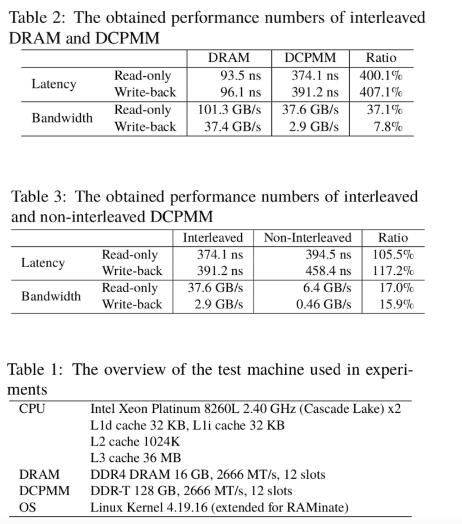
在讨论读写延迟时,Hirofuchi和Takano指出,大多数CPU体系结构都会执行内存预取和乱序执行,以隐藏CPU内核上运行的程序的内存延迟。他们采取了步骤来避免此问题。
为了精确测量延迟,基准程序经过精心设计以抑制这些影响。要测量主内存的读取延迟,它的工作方式如下:
首先,它从目标存储设备分配一定数量的存储缓冲区。为了引起LLC丢失,分配的缓冲区的大小应足够大于LLC的大小。它将内存缓冲区分为64字节的缓存行对象。
其次,它以随机顺序设置了缓存行对象的链接列表,即,遍历链接列表会导致跳转到远程缓存行对象。
第三,它测量遍历所有缓存行对象的经过时间,并计算获取缓存行的平均等待时间。在大多数情况下,由于遍历链接列表中的下一个缓存行对象时,由于LLC丢失而导致CPU内核停顿。该CPU停顿所经过的时间就是内存延迟。”
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。
































