第三代的Instinct MI300系列基于CDNA3架构,分为数据中心APU、专用GPU两条路线,重点提升了统一内存、AI性能、节点网络等方面的表现,再加上先进封装、更高能效,以满足生成式AI的强劲需求。
12月7日凌晨,美国加州圣何塞,AMD Advancing AI大会上,AMD正式公布了Instinct MI300系列加速器的详细规格与性能,以及众多的应用部署案例,将AI人工智能、HPC高性能计算提升到了新的层次。

AI人工智能概念的诞生已经有将近70年历史了,历经长期演化,已经深入人们工作生活的各个角落,只是很多时候感知性并没有那么强,更多时候人们是通过一些节点性时间感受AI的威力。
早期像是IBM深蓝超级计算机战胜国际象棋大师卡斯帕罗夫,近期像是AlphaGo与李世石和柯洁的围棋大战,最近最火爆的当然是ChatGPT引发的大语言模型、生成式AI浪潮。
坦白说,大语言模型眼下似乎有些过热,但从技术和前景的角度而言,AI绝对是未来,不管它以什么形势体现,这都是大势所趋,也是一个庞大的市场,尤其是对算力的需求空前高涨。

一年前,AMD内部估计全球数据中心AI加速器市场在2023年的规模可达约300亿美元,今后每年的复合增长率都能超过50%,到2027年将形成超过1500亿美元的价值,不可限量。
如今看来,这个数据太保守了,AMD已经将2023年、2027年的数据中心AI加速器市场规模预期分别调高到400亿美元、4500亿美元,年复合增长率超过70%。

AMD作为拥有最全解决方案的厂商,可以从各个角度满足AI尤其是生成式AI对于超强算力、广泛应用的需求:
CPU方面有世界领先的EPYC处理器,GPU方面有不断壮大的Instinct加速器,网络方面则有Alveo、Pensando等技术,软件方面还有ROCm开发平台,从而形成一个有机的、完整的解决方案。

AMD早期的计算加速器底层技术都来自和游戏显卡相同的RDNA架构,显然缺乏针对性,于是诞生了专门针对计算的CDNA架构。
第一代产品Instinct MI100系列是AMD首个可为FP32/FP64 HPC负载提供加速的专用GPU,第二代产品Instinct MI200系列则快速进化,在众多超算系统中占据了一些之地。
第三代的Instinct MI300系列基于CDNA3架构,分为数据中心APU、专用GPU两条路线,重点提升了统一内存、AI性能、节点网络等方面的表现,再加上先进封装、更高能效,以满足生成式AI的强劲需求。

Instinct MI300X:1920亿晶体管怪兽 完胜NVIDIA H100

Instinct MI300X属于传统的GPU加速器方案,纯粹的GPU设计,基于最新一代CDNA3计算架构。
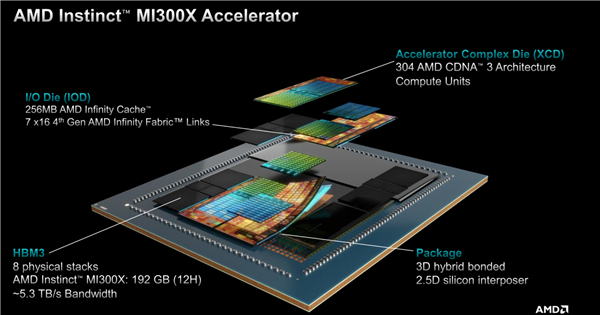

它集成了八个XCD加速计算模块(Accelerator Compute Die),每一个XCD拥有38个CU计算单元,总计304个单元。
每两个XCD为一组,在它们底部放置一个IOD模块,负责输入输出与通信连接,总共四个IOD提供了多达七条满血的第四代Infinity Fabric连接通道,总带宽最高896GB/s,还有多达256MB Infinity Cache无限缓存。
XCD、IOD外围则是八颗HBM3高带宽内存,总容量多达192GB,可提供约5.3TB/s的超高带宽。
AI/HPC时代,HBM无疑是提供高速支撑的最佳内存方案,AMD也是最早推动HBM应用和普及的。
以上所有模块,都通过2.5D硅中介层、3D混合键合等技术,整合封装在一起,AMD称之为3.5D封装技术。
总计晶体管数量多达1530亿个,其中XCD计算核心部分是5nm工艺,IOD部分则是6nm工艺。
顺带一提,结构示意图中位于HBM内存之间的小号硅片,一共八颗,并无实际运算和传输作用,而是用于机械支撑、保证整体结构稳定。
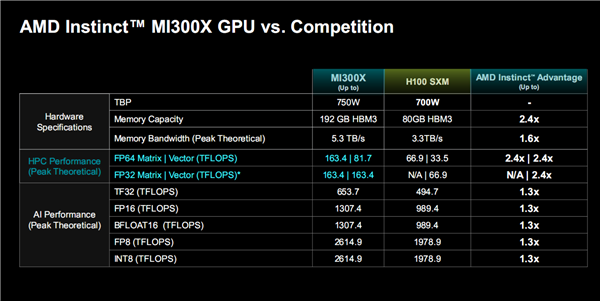
MI300X的各项性能指标都可以胜出NVIDIA H100(H200已宣布但要到明年二季度才会上市所以暂时无法对比),还有独特的优势。
HPC方面,MI300X FP64双精度浮点矩阵、矢量性能分别高达163.4TFlops(每秒163.4万亿次计算)、81.7TFlops,FP32单精度浮点性能则都是163.4TFlops,分别是H100的2.4倍、无限倍、2.4倍、2.4倍——H100并不支持FP32矩阵运算。
AI方面,MI300X TF32浮点性能为653.7TFlops,FP16半精度浮点、BF16浮点性能可达1307.4TFlops,FP8浮点、INT8整数性能可达2614.9TFlops,它们全都是H100的1.3倍。
TF32即Tensor Float 32,一种新的浮点精度标准,一方面保持与FP16同样的精度,尾数位都是10位,另一方面保持与FP32同样的动态范围(指数位都是8位)。
BF16即Bloat Float 16,专为深度学习而优化的浮点格式。
另外,同样适用HBM3高带宽内存,MI300X无论容量还是带宽都完胜H100,而整体功耗控制在750W,相比H100 700W高了一点点。


更进一步,AMD还打造了MI300X平台,由八块MI300X并联组成,兼容任何OCP开放计算标准平台。
这样一来,在单个服务器空间内,就总共拥有2432个计算单元、1.5TB HBM3内存、42.4TB/s内存带宽。
性能更是直接飞升,BF16/FP16浮点性能甚至突破了10PFlops,也就是超过1亿亿次计算每秒,堪比中等规模的超级计算机。
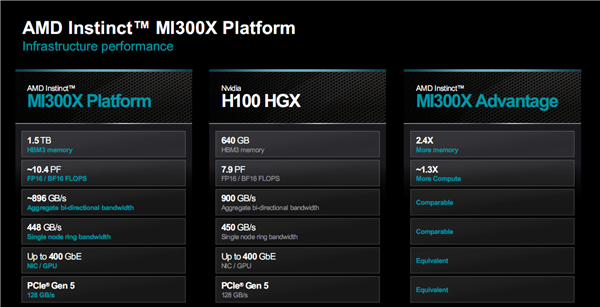
对比同样八颗H100组成的计算平台H100 HXG,它在计算性能、HBM3容量上也有不少的优势,而在带宽、网络方面处于相当的水平。
尤其是每颗GPU可运行的大模型规模直接翻倍,可以大大提升计算效率、降低部署成本。
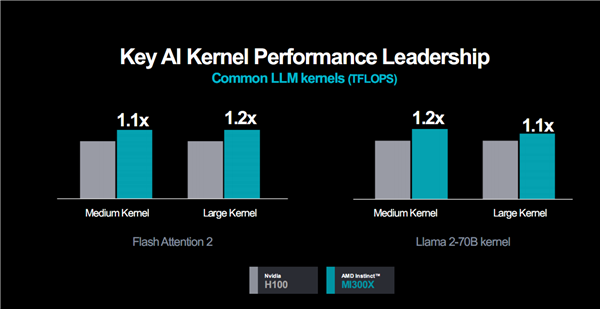
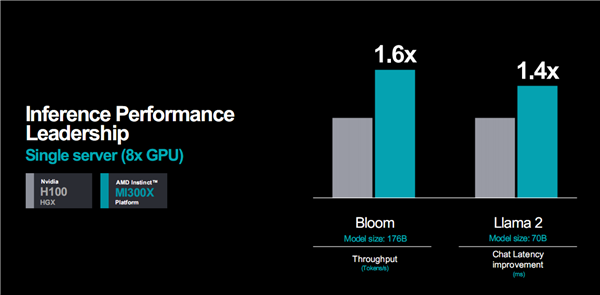


实际应用性能表现方面,看看AMD官方提供的一些数据,对比对象都是H100。
通用大语言模型,无论是中等还是大型内核,都可以领先10-20%。
推理性能,都是八路并联的整套服务器,1760亿参数模型Bloom的算力可领先多达60%,700亿参数模型Llama 2的延迟可领先40%。
训练性能,同样是八路服务器,300亿参数MPT模型的算力不相上下。
总的来说,无论是AI推理还是AI训练,MI300X平台都有着比H100平台更好的性能,很多情况下可以轻松翻倍。



产品强大也离不开合作伙伴的支持,MI300X已经赢得了多家OEM厂商和解决方案厂商的支持,包括大家耳熟能详的慧与(HPE)、戴尔、联想、超微、技嘉、鸿佰(鸿海旗下/富士康同门)、英业达、广达、纬创、纬颖。
其中,戴尔的PowerEdge XE9680服务器拥有八块MI300X,联想的产品2024年上半年登场,超微的H13加速器采用第四代EPYC处理器、MI300X加速器的组合。

在基础架构中引入MI300X的合作伙伴也相当不少,包括:Aligned、Arkon Engergy、Cirrascale、Crusoe、Denvr Dataworks、TensorWare,等等。
客户方案方面,比如微软的Azure ND MI300X v5系列虚拟机,比如甲骨文云的bare metal(裸金属) AI实例,比如Meta(Facebook)数据中心引入以及对于ROCm 6 Llama 2大模型优化的高度认可,等等。

Instinct MI300A:全球首个融合计算APU 冲击二百亿亿次

如果说MI300X是传统GPU加速器的一次进化,MI300A就是一场革命了,CPU、GPU真正融合的方案目前只有AMD可以做到。
相比之下,NVIDIA Grace Hopper虽然也是CPU、GPU合体,但彼此是独立芯片,需要通过外部连接,放在一块PCB板上,层级上还差了一个档位。
Intel规划的融合方案Falcon Shores因为各方面原因已经暂时取消,短期内还是纯GPU,未来再冲击融合。
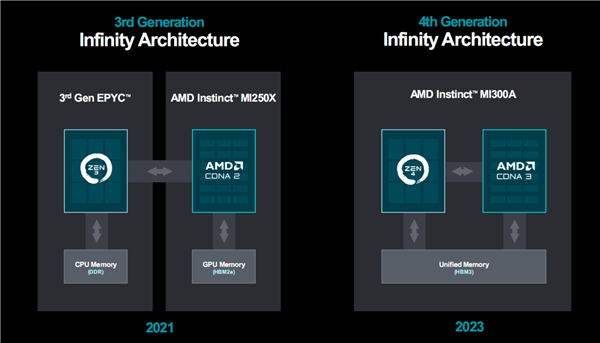
MI300A是全球首款面向AI、HPC的APU加速器,同时将Zen3 CPU、CDNA3 GPU整合在了一颗芯片之内,统一使用HBM3内存,彼此全部使用Infinity Fabric高速总线互联,从而大大简化了整体结构和编程应用。
这种统一架构有着多方面的突出优势:
一是统一内存,CPU、GPU彼此共享,无需重复拷贝传输数据,无需分开存储、处理。
二是共享无限缓存,数据传输更加简单、高效。
三是动态功耗均衡,无论算力上侧重CPU还是GPU,都可以即时调整,更有针对性,能效也更高。
四是简化编程,可以将CPU、GPU纳入统一编程体系,进行协同加速,无需单独进行编程调用。
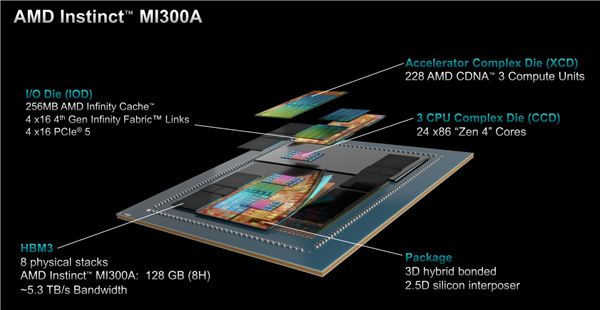

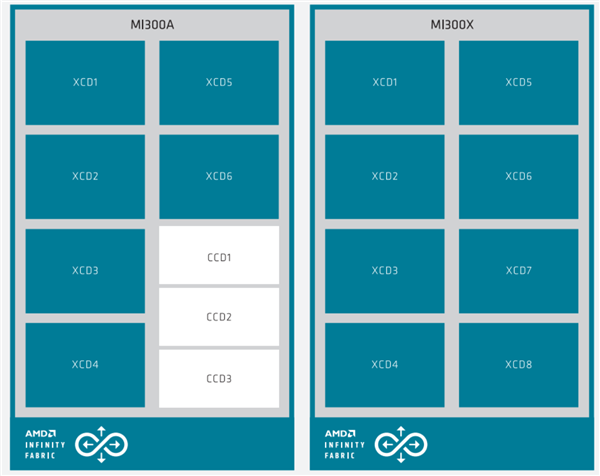
MI300A有六个XCD模块,总计228个计算单元,另外两个在MI300X上属于XCD的位置换成了三个CCD,总计24个CPU核心,后者和第四代EPYC 9004系列的CCD一模一样,直接复用。
四个IOD、256MB无限缓存、八颗HBM3内存、3.5D封装则都是和MI300X完全一致,唯一区别就是HBM3内存从12H堆叠降至8H堆叠,单颗容量从24GB降至16GB,总容量为128GB,但这不影响带宽是同样的5.3TB/s。
晶体管总量1460亿个,其中XCD、CCD工艺都是5nm,IOD部分还是6nm,对外为独立的Socket封装接口。
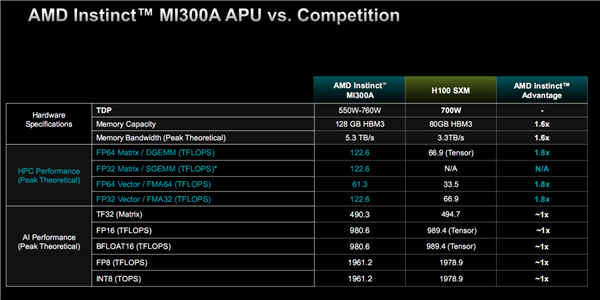
性能方面,MI300A FP64矩阵/矢量、FP32矢量表现都是HJ100的1.8倍(都不支持FP32矩阵),TF32、FP16、BF16、FP8、INT8则都是旗鼓相当。
其中,FP64矩阵、FP32/矢量性能都是122.6TFlops,FP64矢量性能则是61.3TFlops,都相当于MI300X的75%。
TF32性能493.0TFlops,FP16、BF16性能980.6TFlops,FP8、INT8性能1961.2TFlops,同样也是MI300X的75%。
为什么都是75%?因为XCD模块少了1/4,GPU核心自然就减少了1/4,换言之这里都是GPU性能,没有包括CPU部分。
MI300A的整体功耗在550-760W范围内,具体看频率的不同规格设定。
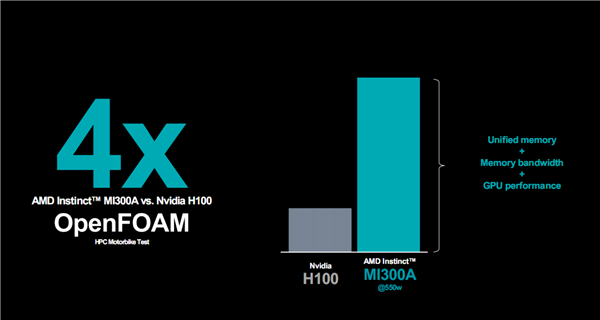
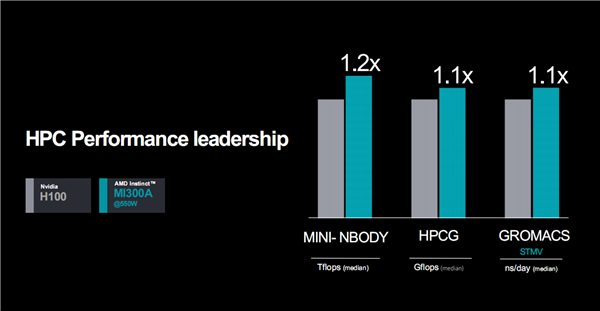
对比H100,MI300A只需550W功耗就能在OpenFOAM高性能计算测试中取得多达4倍的优势,不同实际应用中可领先10-20%。
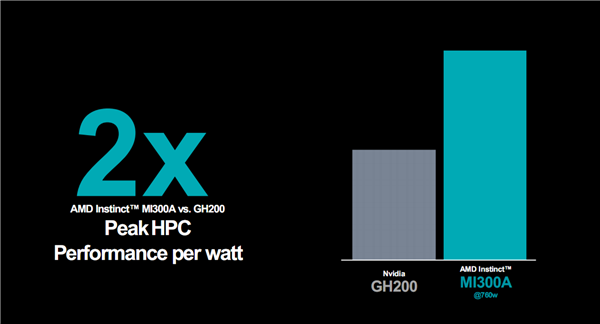
对比最新的GH200,MI300A 760W峰值功耗下的能效优势,更可以达到2倍。

MI300A已经在美国劳伦斯利弗莫尔国家实验室的新一代超级计算机El Capitan中安装。
它的设计目标是成为全球第一套200亿亿次超算,这也是第二套基于AMD平台的百亿亿次级超算。

MI300A的OEM和方案合作伙伴阵容也在不断扩大,目前已有慧与、Eviden(隶属法国Atos)、技嘉、超微。
其中,慧与EX255a是首个基于MI300A的超算加速器刀片服务器,将于2024年初上市。

目前,AMD Instinct系列加速器已经在众多企业、高校、科研机构得到应用,尤其是在超级计算机领域初露峥嵘,11月份发布的最新一期超算500排行榜上拿下了前25名的5个席位,比如第一名的美国橡树岭国家实验室Frontier、第五名的芬兰LUMI,都应用了MI250X。
同时,Instinct加速器还占据了绿色超算500排行榜上前10名中的7个席位,包括6个MI250X、1个MI210,其中Frontier TDS第二、LUMI第三,足可见其高能效。
这也是AMD 30x25目标的一个重要节点——AMD致力于在2020-2025年间将服务器处理器、AI/HPC加速器的能效提升多达30倍。
软件生态:ROCm 6全面进化 软硬结合提速8倍
好马配好鞍,一如游戏显卡必须有驱动程序配合才能释放性能潜力,AI/HPC加速器的发挥也离不开开发平台和工具的全力辅佐。


AMD ROCm就是这样的一套开放软件平台,如今来到了全新一代ROCm 6。
它重点针对大语言模型额和生成式AI进行优化和提升,以及强化支持开放开源、拓展生态支持、加入更多AI库等等。

比如在大语言模型优化方面,支持开源大模型推理加速框架vLLM,并优化推理库,延迟性能提升可达2.6倍;
支持的高性能图形分析与学习框架HIP Graph,优化运行时,延迟性能可提升1.4倍;
支持高效内存的注意力算法Flash Attention,优化内核,延迟性能可提升1.3倍。
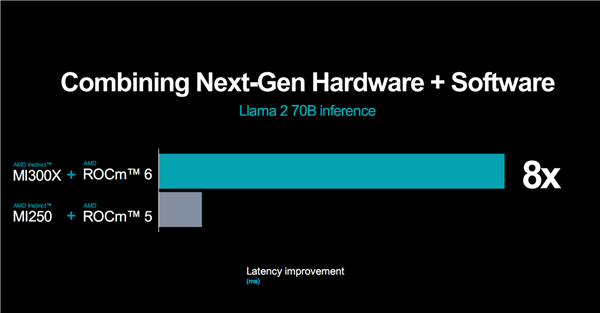
新一代硬件加新一代开发平台的威力是相当猛的,比如MI300X、ROCm 6的组合相比于MI250X、ROCm 5,运行270亿参数Llama 2大模型推理,延迟性能可改善多达8倍!
当然,ROCm 6平台也会陆续支持老平台硬件,进一步挖掘潜力。

而对标竞品,比如130亿参数的Llama 2大模型,MI300X的延迟性能相比H100可以领先20%。

生态支持方面,ROCm 6也在快速拓展,尤其是基于AMD一贯以来的开放开源路线,一方面积极为开源社区贡献自己的开发库,另一方面可以充分利用各种开放开源的AI模型、算法和框架,包括Hugging Face、PyTorch、TensorFlow、Jax、OAI Triton、ONNX,等等。
其中,OpenAI会在即将发布的Triton 3.0版本中正式支持AMD GPU,未来和你对话的ChatGPT背后可能就是AMD Instinct在驱动。

总的来看,AMD新一代Instinct MI300X/MI300A加速器在硬件上有着艺术级的精妙设计和世界领先的计算性能、能效,尤其是真正融合的APU走在了行业的最前列,开拓了全新的可能。
再加上EPYC CPU处理器、网络方案的配合,为生成式AI推理、训练和应用提供了强大的算力平台基础。
在软件开发、生态合作上,AMD同样积极与时俱进,开放拥抱社区、拥抱产业,简化开发与应用流程,大大增强了自身竞争力,前途无量,值得期待。
PS:
至于MI300系列是否会有“中国特供版”,AMD的官方回复如下:
“中国市场对AMD很重要。我们今天没有宣布专门针对中国市场的特别产品。 ”

声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。