英特尔与美光日前作出的声,公开了其全新3D XPoint(即交叉点)非易失性内存技术。
目前的主流内存技术分别为DRAM(能够由处理器快速访问的内存)以及NAND(即固态存储方案),二者自诞生至今都已经过去了几十年。尽管最近几年来,存储单元设计的不断演进已经将制程工艺缩小到了20纳米甚至更低水平,但DRAM与NAND的基础性物理运作机制并没有发生改变,而且这两项成果都在技术层面存在着一定局限。DRAM能够提供纳秒级延迟水平与几乎无限的耐久能力,但其同时也存在着存储单元较大而价格昂贵、存储单元拥有易失性以及功耗较高等问题。由于DRAM存储单元需要进行持续更新,各个单元当中所承载的数据无法以稳定状态存在,这就要求我们投入大量电力供给、而DRAM也并不适合应对永久性存储类任务。在另一方面,NAND的延迟水平更高(特别是写入操作),写入周期有限,但其存储单元为非易失性而且整套结构更为高效,这使其拥有较低使用成本且适合用于永久性存储。
将DRAM与NAND在系统层面上进行结合的架构能够充分发挥二者的固有优势,因此现代计算机会选择利用DRAM作为内存/缓存机制,而NAND则负责处理数据存储。然而,DRAM与NAND之间仍然存在着延迟水平与存储容量两大鸿沟,因此目前的难题在于:如果我们能够将DRAM与NAND的自身优势在芯片层面进行整合,结果会是怎样?目前整个存储技术行业正在积极构建下一代内存技术,其目标就是开发出一套既具备低延迟与高使用寿命水平,又能够实现小型可扩展存储单元的新型内存方案。
时至今日,已经有Crossbar以及Nantero等一大波初创企业开始探讨并展示其下一代内存技术成果,但尚没有哪家DRAM与NAND供应商着手推出自己的解决方案。然而英特尔与美光日前作出的声明扭转了这一切,双方于本周公开了其全新3D XPoint(即交叉点)非易失性内存技术。

首先而且最重要的是,英特尔与美光双方明确表示,3D XPoint的定位并不属于NAND或者DRAM技术的替代性方案。而且在此基础上,两家公司更多是在强调3D XPoint的具体应用范畴,其更接近于NAND而非DRAM。它应该成为一种补充性技术,旨在解决DRAM与NAND之间延迟水平与成本差异所带来的两难抉择。基本上,3D XPoint是计算机架构当中的一种新型层级,因为它既能够作为速度较慢的非易失性内存、亦可以作为速度更快的存储机制。
DRAM 3D XPoint NAND
使用寿命(全盘写入次数)10^1510^710^3
读取延迟纳秒级10纳秒级约100微秒级
英特尔与美光双方宣称,3D XPoint能够提供千倍于当前NAND产品的使用寿命水平。假设这里的参考对象为现代(15纳米至20纳米)MLC NAND,那么其使用寿命将达到数百万次全盘写入; 不过在市场营销材料当中,我们看到相关产品的写入次数可以达到数千万次。如果我们假定其全盘写入次数为300万次(即1000倍于现代MLC闪存),那么一块基于3D XPoint技术的256 GB驱动器将能够提供总计高达768 PB的数据写入能力。这相当于五年内每天写入420 TB数据,或者每秒写入4.9 GB数据。对于目前依赖于NAND技术的存储设备而言,3D XPoint将消除任何可能出现的使用寿命问题——不过相对于耐久性几乎无限的DRAM来说,3D XPoint仍然要略逊一筹。企业最终是否会利用3D XPoint取代DRAM还是要取决于实际应用情况,特别是对于那些要求使用DRAM的企业级工作负载来说更是如此。
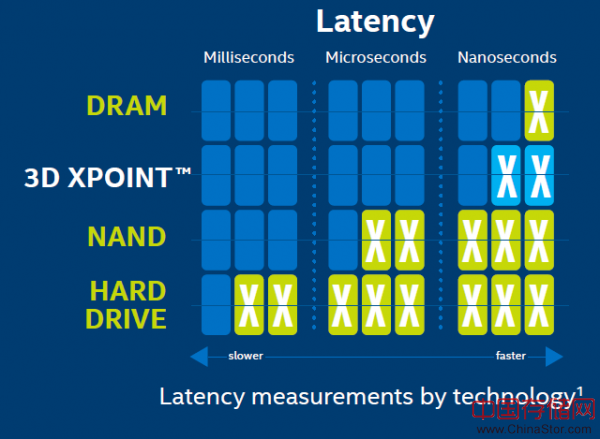
3D XPoint的延迟水平在10纳秒级别,但英特尔与美光双方并没有明确指出这一数字到底来自读取延迟还是写入延迟。从英特尔方面提供的图表来看,10纳秒级别应该是指读取延迟,因此NAND写入延迟的计量单位应该是毫秒(一般来讲,全页写入的延迟为1到2毫秒),而图表中列出的NAND延迟为数十微秒的说法与NAND的读取延迟相符。写入延迟往往远高于此,再结合英特尔与美光双方作出的“速度可达NAND上千倍”的说明,那么我们猜测3D XPoint的写入延迟应该在100纳秒级别甚至是毫秒级别。不过更复杂的是,3D XPoint以bit为访问层级,而NAND以页为访问层级,因此在不考虑外界因素的前提下比较二者的延迟水平相当困难。无论如何,3D XPoint的性能表现应该更接近于DRAM而且优于NAND,不过考虑到英特尔与美光都没有就延迟给出明确参数,因此我们作出断言恐怕还为时尚早。
与此同时,与目前已经存在的大部分下一代内存技术不同,3D XPoint走得最远、而且已经不再单纯是纸面或者实验室环境下的理论产物。英特尔与美光目前已经开始制造第一代样品晶粒,负责代工的是双方的合资公司、位于犹他州的Lehi代工厂。其晶粒的存储容量为128 Gbit(即16 GB),相比之下各初创企业能够拿出的实际产品只有数十MB容量。该晶粒以20纳主制程工艺制成,其中包含两层,并可能会在未来随着光蚀刻尺寸的缩小通过增加层数进一步实现容量扩展。
这座犹他州代工厂目前正在生产20纳米NAND,因为英特尔方面尚未开始投资兴建16纳米生产线,而3D NAND生产线则将在美光的新加坡代工厂全面上线。不过我们尚不清楚后者每月20000块晶圆的生产能力是否将会被全部用于生产3D XPoint。根据我个人的猜测,3D XPoint将最终占据犹他州代工厂的整体晶圆产量,具体取决于市场对于这项新技术的反应以及英特尔与美光感受到的实际发展前景。3D XPoint在生产制造方面确实需要使用相当一部分新设备及整套新型材料供应体系,但英特尔与美光表示整个过渡与切换为新型NAND节点非常相似,而且仍有一部分现有设备能够继续进行使用。
两家公司并没有对每GB使用成本作出任何说明,不过由于3D XPoint的功能定位介于DRAM与NAND之间,因此其价格应该也会据此进行制定。NewEgg为DRAM统计出的每GB使用成本大约在5到6美元之间,而高端企业级SSD的每GB使用成本则为2到3美元。与此同时,消费级SSD的每GB使用成本最低可达0.35美元,但这样比较并不是特别公平,因为至少3D XPoint在刚刚面世时肯定只会针对企业级应用场景。根据我的个人猜测,第一款基于3D XPoint技术的产品每GB使用成本大约为4美元,并可能会考虑到未来一年中DRAM与NAND的价格下调而略微有所削减。
技术解析:3D XPoint是如何工作的?
3D XPoint的工作原理与NAND存在着根本性的不同。NAND通过绝缘浮置栅极捕获不同数量的电子以实现bit值定义,而3D XPoint则是一项以电阻为基础的存储技术成果,其通过改变单元电阻水平来区分0与1。
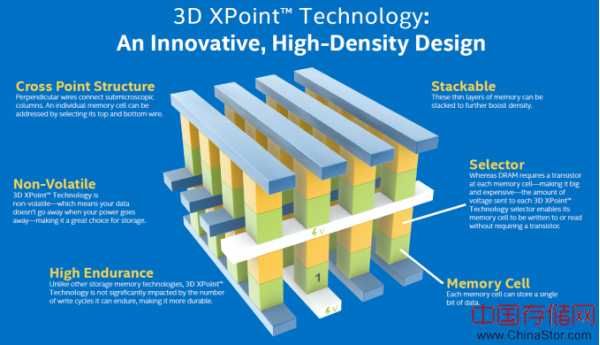
3D XPoint的结构非常简单。它由选择器与内存单元共同构成,二者则存在于字线与位线之间(因此才会以‘交叉点’来定名)。在字线与位线之间提供特定电压会激活单一选择器,并使得存储单元进行写入(即内存单元材料发生大量属性变化)或者读取(允许检查该存储单元处于低电阻还是高电阻状态)。我猜测,写入操作要求具备较读取更高的电压,因为如果实际情况相反,那么3D XPoint就会面临着上在读取存储单元时触发大量材料变化(即写入操作)的风险。英特尔与美光双方并没有透露内部读取/写入的具体电压数值,不过根据我们得到的消息,其电压值应该低于NAND——后者需要利用约20伏电压来编写/擦除以创建出足够通过绝缘体的电场电子隧道。而这种较低的电压要求自然也能够使得3D XPoint拥有比DRAM以及NAND更低的运行功耗。
顾名思义,3D XPoint的存储单元可以以3D方式进行堆叠,从而进一步提升存储密度。目前第一代晶粒样品使用的是双层设计方案。双层听起来实在有些寒碜,特别是考虑到目前的3D NAND芯片已经拥有32层,且逐步开始向48层进军。不过3D XPoint的构建方式完全不同,直接进行层数比较显然并不科学。
3D NAND在制造过程中首先加入沉积导电层,而后再在每一层之上添加绝缘材料。只有在全部层沉积完毕之后,整个“单元塔”才能以光刻方式进行定义,而后再在高纵横比蚀刻孔内填充通孔材料以实现各层内存储单元的彼此互通。相比之下,3D XPoint的每一层都需要进行光刻与蚀刻(即在各层之上重复同样的流程),接下来再对下一层进行沉积。这种方式牺牲掉了3D NAND所带来的一部分经济优势(即光刻步骤较少),但3D XPoint却同时带来了远高于纯光刻技术所能实现的出色存储密度。
英特尔与美光公司指出,未来工艺尺寸伸缩将同时出现在光刻与层3D堆叠这两个方面。横向与纵向的规模可调整能力将成为关键,保证其未来仍然具有进一步可延展性,这是因为基于氩氟的传统多模式浸没式光刻技术在10纳米级别上已经失去了经济性优势,而目前尚未出现任何明确的继任技术可供选择。当下业界普遍将希望寄托在EUV身上,而英特尔与美光则确认称,3D XPoint将(不出所料)兼容EUV光刻,而且存储单元设计尺寸可以最大缩水至个位数纳米级别——同时不会对使用帮助/可靠性造成显著影响(事实上,随着物理尺寸的下降,其在某些方面反而有所改善)。不过在未来几年内,我们恐怕仍然无法利用EUV实现批量化生产。首批EUV生产的主要重心也将放在逻辑层面,这一方面是因为其设备成本实在太过高昂,另一方面也是因为逻辑无法像记忆体般进行垂直绽放、因此可能导致散热问题。
从理论层面讲,3D XPoint也支持多层单元设计,但英特尔与美光双方目前并不打算追求这条路线。虽然在实验室当中实现多个电阻层级并不是件太难的事,但其实际难度还是要远远高于保证生产的数万片晶圆当中、每个晶粒都具备必要的特性以实现双层单元操作。相比之下,这一思路很像是二十年前每单元2 bit机制刚刚出现在NAND领域的状况,因此目前英特尔与美光暂时会将注意力集中在光刻技术及3D伸缩方面,从而提高存储密度及成本效益。不过相信在未来,多层单元设计也将逐步出现在3D XPoint当中。
而与NAND在架构上的最大区别在于,3D XPoint实际上是以bit层级进行访问。在NAND当中,整页(在最新节点中为16KB)必须一次性进行编程才能存储1 bit数据。而更糟糕的是,我们必须要在块层级(至少包含200个页)执行擦除操作。如此一来,NAND就需要使用更为复杂的垃圾回收算法,从而更为高效地实现性能水平。然而无论算法多么精巧,处于稳定状态的驱动器在性能上仍然会因此受到影响,因为必须采用固定的读取-修改-写入周期才能对块中的单一页进行擦除。而作为以bit为基础访问单位的3D XPoint来说,其并不需要配合任何垃圾回收机制即可高效运作,这不仅极大简化了控制器与固件结构,更重要的是还将实现更高性能水平与更低功耗需求。
我个人怀疑,在最终产品——特别是面向存储需求的产品——当中,3D XPoint仍然会保留一部分逻辑页以降低追踪操作带来的负担,这是因为在bit层级上进行数据追踪将需要大量高速缓存作为配合。然而,英特尔与美光公司已经在声明当中就此作出了明确回应,表示日前发布的公告仅仅属于一项技术性结论。两家公司拒绝就基于这项新技术的未来面世产品发表任何评论。换句话来说,这两家企业将各自打造自己的产品方案,并预计将在明年正式将其交付至广大用户手中。
内存单元:3D XPoint背后的秘密
从子阵级角度出发,3D XPoint的运作方式还算比较容易理解,但探究大量属性变化过程中内存单元之内的实际动态则是个非常复杂的问题。从个人角度出发,我能想到的就是需要通过两种方式实现这一目标——以物理方式利用外部刺激调整存储单元属性,从而实现晶体结构变更; 或者是以化学方式对单元内的材料属性进行调整。在发布会之后的对话环节当中,我们得到的消息是3D XPoint所使用的并非相变材料,这就消除了一种潜在可能性——即3D XPoint利用相变材料通过单元晶体结构变化来实现电压切换。英特尔与美光选择的方式也极具现实意义,因为引导稳定晶体结构发生变化很可能意味着对不同原子结构长度进行频繁调节,而这有可能影响到存储单元之间连接材料,最终导致使用寿命降低。考虑到这一点,惟一可行的就只有化学调整方式了,更具体地讲对存储单元中的bit电子结构进行调整,从而使其出现电阻差异。
经过一系列研究,我想咱们不妨在这里就其实现原理展开一番探讨。
自旋交叉
根据以往的经验,我自然而然地想到了自旋电子与自旋交叉化合物的应用。简而言之,这意味着此类材料拥有两种不同电阻级别,具体取决于结构内电子层级中的电子状态。而外部刺激(包括温度、电压以及磁场的变化)则用于实现两种电子状态之间的切换。
接下来的内容可能有些艰深,我们最好是从单个过渡金属原子出发进行考量。根据该金属原子周边的局部排列,金属的键合轨道部分会充斥着大量电子:
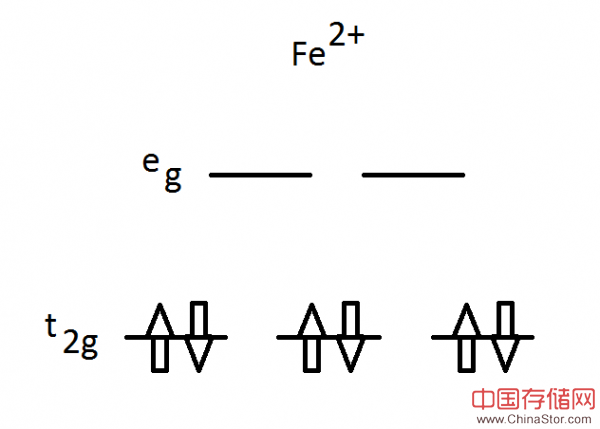
这里是一个处于2+价环境下的铁化合物分子,其主要成键轨道为t2g(低能量)与eg(高能量)。根据Pauli提出的不相容原理,6个电子配对构成三条轨道,而且每个电子对中的一个电子“自旋加快”、另一个则“自旋减慢”。这就是我们所说的基态,也被称为低自旋状态。其整体自旋值S等于0,因为一个电子的自旋值1/2会被另一个电子的自旋值-1/2所抵消。
此原子的另一种模式则为高自旋态,其中2个电子转移到了较高的键合轨道当中,而总体自旋值S=2:
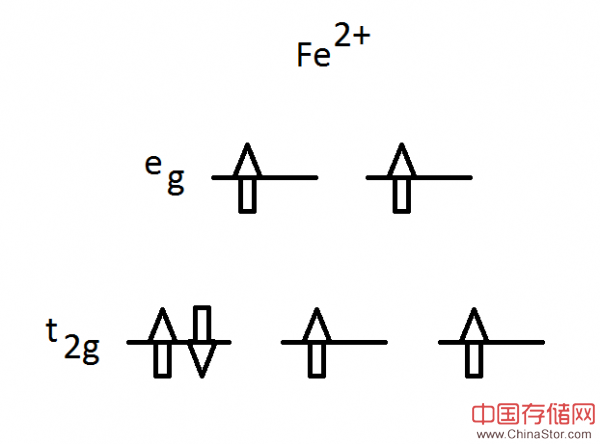
由于外部刺激的存在,其中将有2个电子翻转自旋并占据高能量eg轨道,而这也就是所谓“亚稳定”状态。根据周边原子的实际排列,这种状态实际上也可以表现得非常稳定,但却与原始基态在性质上存在很大的不同。
不过将这种原理推广到大量材料之上,从原则上讲非常困难。简要概括,各类研究论文指出自旋交叉化合物可以直接进行对接并实现电阻变化,但与这类操作相关的大部分论文都属于化工学科,探讨的也主要为碳纳米管、石墨烯层或者有机链等对象。
图片来源:M. Urdampilleta等所著之《自然材料》第十章502节(2011年)
在这篇论文当中,低自旋/高自旋状态将提供或不提供两种极性之间的导电率,具体取决于金属原子的实际性质、电阻、特性以及/或者平台稳定性水平。英特尔公司需要开发出这样一种材料,其能够通过电压变化而非外部刺激实现编程,而这显然将复杂性提升到了新的高度。一般来讲,自旋交叉化合物具备特定的温度窗口,在不同温度下其电子可以在高状态与低状态之间往来切换,这意味着温度因素对其稳定性存在直接影响。
从这一点出发,材料的可延展性与基础特性成为实现大规模自旋交叉的主要障碍,特别是在同时采用碳纳米管的情况之下。如果要对大量金属材料进行延展,那么我们需要为其提供一个单独的金属环境进行批量处理,带线(与间隙)会令原本单纯的轨迹概念变得更加模糊,因此我们根本无法将其纳入至存储单元之中。英特尔公司还指出,他们的技术能够让每个存储单元承载多bit,而自旋交叉的排布问题能够利用电子隧道机制加以解决,从而达成构建存储单元的目标。
自旋转矩效应(简称STT)
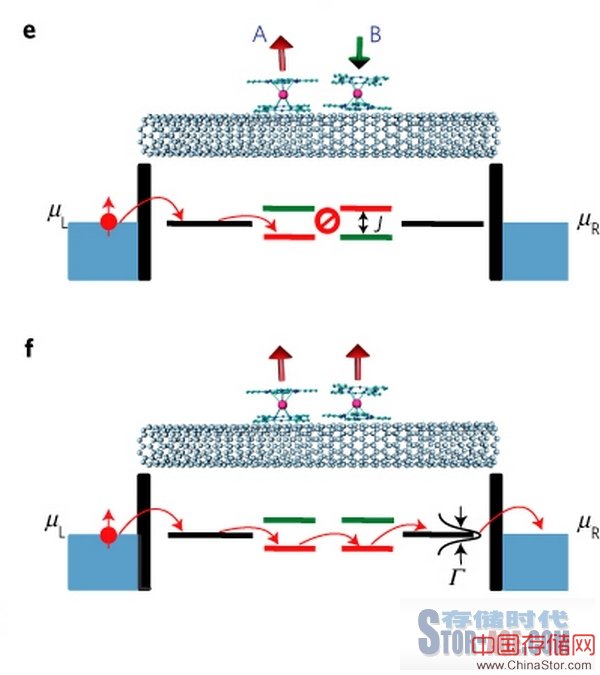
内存单元的自旋转矩效应取决于单元两种状态之间的电阻水平,外加在存储单元内部控制磁性的能力。简而言之,如果大家对某种材料的磁性布局作出调整,也就能够同时调查其电阻并将其作为记忆体加以使用。
而更为具体的解释是,自旋转矩效应的长期存在依赖于被称为自旋极化电流的性质。电子自旋从根本角度讲分为两种方向,即自旋加速与自旋减速。一般的电流通常由这两类方向均匀混合,这样整体看起来就呈现出非极化电流的形式(即不存在整体自旋方向性)。而当一股非极化电流通过一层厚厚的磁性材料时,其立刻开始呈现出极化特征。如果这种极化电流随后通过处于不同电子密度状态的薄磁层,那么电流的极性则会产生磁性,从而使更多电子自然进入反向自旋状态。
由于厚磁层具有恒定的磁场向性,而薄磁层(或者称作自由层)能够进行翻转(具体取决于材料本身),因此这两者相结合后所产生的电阻即可作为记忆体单元使用。
图片来源:《STT-RAM作为高效节能主内存替代方案的可能性评估》,作者:Kültürsay等。
论文指出,自旋转矩效应方案的优势在于其能耗水平低于DRAM,但性能表现则与后者基本相当。而这项技术的实现障碍主要源自以纳米光刻这样极为微小的立足点构建永久磁体的能力,外加如何将众多如此微小的磁体以彼此接近的方式加以排布(类似于磁盘驱动器当中的bit单位)——这有可能导致其中一部分发生意外翻转。除此之外,也并不清楚使用这种方法能够提供每单元单一二进制bit以上的容纳能力。而且现有研究表明,其需要同时使用一个控制晶体管方能正常起效。而英特尔方面已经明确指出,3D XPoint并不使用任何控制晶体管。
自旋转矩效应技术的公开发展历史最早可追溯到2011年由高通公司推出的1 Mb IC以及2012年来自Everspin公司的64 Mb模块,不过二者始终未能投入实际生产。
导电桥接技术(简称CB)
对通路电阻进行调整的最简单办法之一就是通过物理变化将电子运动路径几乎完全阻断。导电桥接技术(或者被称为可编程金属化单元)则采用类似于电解的技术在电极之间创造出一道纳米桥,从而降低单元电阻。
在一个导电桥接单元当中,一层薄电解质膜(过去一直以液态方式存在,但现在也可以呈现为固态)处于活性与惰性电极之间。当惰性电极被施加一个负偏压时,电解质中的金属离子会被不愿为金属原子。当析出并连接的金属原子数量达到一定程度后,其会形成一条位于两个电极之间的导线。而要切断这条导线,我们需要施加反向电位差,从而将导线中的原子重新氧化成电解质的组成部分。最终的电极-电解质-电极组合仍然具备导电能力,但其电阻要高于前面提到的存在导线的情况。

不过对于任何一位对于电解机制比较熟悉的朋友来说,以上概括性描述同时也带来了大量问题。首先,也许存储单元当中使用的是液态材质,但我们更倾向于假定需要处理的是处于固态材料当中的移动离子,其活动空间介于各嵌入点之间(也就是晶格/框架之间的空间)。不过在我个人看来,真正值得仔细推敲的还是要数上述表达中提到的“导线”一词。通常来讲,通过电解实现的原子析出往往缺乏指向性——我们是领先不同晶体面的活动来推出析出,这就导致离子扩散以多向性方式进行,不过根据实际晶体面的增长情况、电极指向会略有偏差。在这种情况下,分叉线就会出现——类似于闪电的表现形式。而在对不同电极进行彼此连接时,或者至少是在电子隧道的长度之内,导线本身的电阻差异(从高电阻到低电阻)也相当巨大。不过随着导线的持续构建,电阻值也会不断降低。考虑到这一点,建立导线这种处理方式确实能够为每个单元提供多bit容纳能力,但正如我之前所提到,其实施难度也相当之大。另一项因素在于逆转的过程——通常是由同样的材料作为离子提供活性电极,但这意味着电极本身基本上也具备可溶解性。通过研究我们看到,这恐怕会对产品的使用寿命造成影响。
而在导电桥接技术的优势角度,其在理论上能够实现低于浮栅单元的物理尺寸、而布局也相对简单。根据报告所言,其能够在功耗与性能水平方面较当前NAND改善达数个量级。
考虑到上述问题与优势的存在,我认为导电桥接技术目前应该作为3D XPoint方案的优先使用对象。美光公司曾于2002年的官方许可当中作出过相关暗示,而且2014年美光分析师大会上展出过的幻灯片资料也提到了他们如何克服我之前提到的一些问题:

图片下方列出的正是当时正处于研发状态的存储单元,演示材料中确实提到了桥接技术的存在。为了确保活性电极不会在逆向编程过程中被“吃掉”,技术人员设置了一套大型离子库供其调用。另一个电极则尺寸很小,以便于导线能够定向构建。只要整个电解质层够小(数个单分子层),那么读取/写入操作的速度将极快、实现也将非常容易。
未来发展
总结而言,如果我们快速跳转至2015年2月,那么请注意美光公司在其分析师会议当中公布的另一份演示资料:

在这幅图片的下半部分,我们可以明显看到美光公司正着眼于左侧基于自旋转矩效应的记忆体方案,而亦有分析师报告指出图片右侧的RRAM单元很可能使用的就是导电桥接技术。而在本周公布的3D XPoint演示资料中,多位分析人士认为最优先的实现选项很可能是利用二极管探测实际电阻特性。
考虑到公告强调称目前正在进行的技术研发从根本角度讲迥异于此前有过的尝试,而3D XPoint产品进入批量生产的最大难关在于制造材料,我最终无法判断其具体采用了哪一种实现方式。从可能性方面来看,英特尔与美光双方也许使用的是导电桥接技术打造出了这款产品。最为精确的细节将被牢牢掌握在英特尔与美光手中,因为毕竟这项技术成果从概念到产品的整个推进流程殊为不易——考虑到前面提到的2002年发布导电桥接技术许可,整个研究周期已经延续了整整十年。
估算3D XPoint的晶粒尺寸
说到现在,大家一定发现我是个喜欢刨根问底的家伙,接下来要关注的自然就是晶粒尺寸了。DRAM与NAND供应商向来不愿公布此类信息,所以我只能通过自己的方法尽可能对晶粒尺寸进行估算(好吧,其实具体用到的也就是初中水平的几何知识,所以我也不指望靠这个扬名立万)。晶粒的大小是决定成本效益的关键性因素,因为它直接关系到每块晶圆所能产出的存储容量GB数字,因此我们也会在对不同技术及流程节点进行比较时将其作为一项重要指标。

我从The SSD Review网站处借用了上面这幅图片,因为老实讲我自己保存的晶圆图片(包括其它一些图片)拍得都不怎么样,几乎没办法直接当作参考对象进行观察。Sean是一位专业摄影师,因此由他负责拍摄到了这幅英特尔与美光所展出的3D XPoint产品照片——很清晰,也很美观。有了这份素材,我们就能更轻松地确认晶粒尺寸了。
根据我的计算,这片晶圆上的横向晶粒数量为18个,纵向则为22个,而晶圆本身则属于面积为227平方毫米的标准300毫米晶圆。在进行晶粒切模时,我们应该考虑到不同晶粒之间预留的下刀空间,因此各晶粒的实际总面积应该在210到220平方毫米之间。晶圆面积利用率大约为90%,这要比平面NAND高得多,因为其大部分外围电路都位于记忆体阵列的底部。

IMFT 20纳米128 Gb MLC NAND晶粒
比较来看,英特尔与美光的20纳米128 Gb MLC NAND晶粒在单片晶圆中的总面积为202平方毫米,其实际利用率约为75%。通过这一比例,我们可以计算出3D XPoint中的128 Gb内存阵列的总面积约为190平方毫米,而存储容量则与面积约为150平方毫米的平面NAND阵列基本相当(由于128 Gb 3D XPoint晶粒由双层结构构成,而128 Gb MLC NAND晶粒则在每个单元中容纳2 bit,因此层数与每单元bit存储数量恰好抵消)。从内存阵列的角度来看,采用固定制程尺寸(即光刻)的NAND晶粒拥有更高的存储密度,但单就这一点我们仍然很难判断这是由单元设计本身所造成、还是受到其它因素的影响。相较于2D平面制程,字线与位线同金属间层之间的连接层可能需要战胜一些额外的面积(至少参考3D NAND情况是如此),这可能也解释了3D XPoint为何会在存储密度上略逊于NAND。
不过我们还要等待更多SEM照片来进一步观察3DeXPoint阵列的排布情况,及其同NAND在单元尺寸及整体密集方面的对比结果。当然,除了具体单元与晶粒尺寸之外,还有很多其它因素影响着产品的总体制造成本,不过我会在进一步了解到生产设备及半导体制造流程的实际情况之后再作出深入分析。
3D NAND的未来命运
以上分析结果显示,3D XPoint并非3D NAND的替代性产品,至少在可预见的未来不会威胁到后者的生存。除此之外,英特尔与美光双方也在提及3D XPoint对3D NAND的影响时明确指出,其定位属于介于DRAM与NAND之间功能空缺位置的新型利基内存方案。两家公司目前仍在积极推动3D NAND产品在明年的全面上市,并为未来几代3D NAND产品制定出坚实的发展路线图。
正如我之前曾经提到,3D XPoint阵列的构建方式与3D NAND完全不同。根据我的个人理解,前者的使用成本更高,因此第一代3D XPoint产品仅仅采用了双层结构而非像3D NAND那样以大规模光刻制造技术实现数十层结构。除非3D XPoint也能获得与3D NAND相似的制造方式(即同时添加多层并一次性完成光刻处理),否则我认为3D XPoint短期内在成本方面仍然无法与3D NAND相抗衡——不过再次强调,3D XPoint的短期发展规划并非作为NAND芯片的继任者存在。
不过未来十年内实际走向如何则是另一码事了。3D NAND目前面临的零通孔电流难题可能是目前最大也是最广为人知的发展障碍。基本上,3D NAND各个“单元塔”(即层堆栈,目前的三星与英特尔-美光3D NAND芯片皆为32层结构)内的传输通道为单一通孔,电流需要通过各个通孔到达每个独立存储单元。但问题是,随着通孔长度的不断增加(即整体结构中层数的增长),电流将很难达到顶部单元,因为传输过程会引发干扰效应,进而降低通过通孔的整体电流(也就是所谓‘零通孔电流’)。如果大家有兴趣查看与这一问题相关的详尽实验数据,我建议各位参阅3D Incites与Andrew Walker就此议题发布的博文。
由于大多数厂商目前还没有开始进行3D NAND方案的批量生产,因此短时间内这项技术应该还不会遇到发展瓶颈。当下东芝-SanDisk公司的15纳米NAND已经开始使用由128个存储单元构成的通孔结构,但与其它半导体技术一样、3D NAND也将最终面临尺寸伸缩方面的难题。这种情况也许会在未来五年、十年乃至二十年中出现,但对于3D XPoint这样一项以成熟与可扩展能力作为主要卖点的技术成果而言,及早考虑并解决此类障碍显然非常重要。
具体产品
在本次会议中,英特尔与美光双方在声明中提到的内容全部围绕底层3D XPoint技术展开。基于这项新技术的产品将在下一年年内揭开面纱,而且两家企业目前都对具体细节守口如瓶——仅仅给出了一点提示。首先,英特尔与美光之间的协作关系只停留在内存技术层面,而且两家公司正在着手开发自己的3D XPoint产品——类似于双方在SSD/NAND业务方面的作法。从技术层面讲,这意味着两家公司将在市场上存在竞争关系,不过可能性更高的情况是、二者会各自通过独特的实现方案利用3D XPoint技术打造自家最终产品。
值得注意的是,英特尔公司在现场演讲与问答环节当中都着重强调了NVMe技术。英特尔公司自该项技术诞生以来就一直扮演着热情的倡导者角色,其同时也是第一家于去年凭借DC P3700及其衍生方案批量发售NVMe SSD产品的厂商。尽管NVMe迄今为止一直被作为主流非易失性内存而与NAND保持着紧密关联,但其核心架构立足于下一代内存技术,因此具有更为出色的延迟水平表现(毕竟NVMe的全称为Non-Volatile Memory Express)。考虑到软件接口在过去近十年当中一直没有出现显著变化,NVMe的诞生很明显开始将包含NAND在内的更多因素纳入了设计考量。
随着NVMe产品的出炉,我们明显将迎来基于PCIe SSD形式的3D XPoint解决方案。这些方案有可能以接入卡抑或是2.5英寸驱动器的形式出现,不过在我个人看来,接入卡的可能性应该更高一些(至少在早期阶段是如此),而这主要是由于连接器的局限所导致。U.2(也就是原先的SFF-8639)只支持四条PCIe 3.0通道,这使得其实际传输带宽仅在每秒3.2 GB左右。NAND闪存目前的读取传输能力已经使得上述带宽设置趋于饱和,因此3D XPoint在拥有更为出色的写入与随机IO性能的情况下,多余的性能空间很可能会由于传输接口的能力所限而遭到浪费。接入卡并不会受到U.2局限的影响,而且能够支持十六通道以及由此实现的高达每秒10 GB传输带宽,但其缺点在于服务能力有限——因为接入卡无法像2.5英寸驱动器那样实现前载。由于企业客户已经开始使用接入卡(Fusion-io公司一直致力于生产接入卡这一类产品),我认为真正需要利用3D XPoint产品承载自身工作负载的企业客户并不会被服务能力所束缚。而在另一方面,我猜测英特尔公司也会推出与U.2类似的八通道标准,但要想真正得到普及、这类新规范还需要整个行业的全面支持。
由于英特尔已经成为合资公司中的另一位参与者,可以肯定3D XPoint将迎来全面支持以及在平台端所需要的大力推动。英特尔方面能够将更多PCIe通道以及/或者回事机制纳入到PCIe 4.0标准的开发当中,从而在即将推出的后续平台上实现更为可观的传输带宽水平,并借此为3D XPoint的市场化进程铺平道路——这样的能力显然是其它内存供应商所不可能具备的。

AgigA公司的DDR4 NVDIMM:也许会成为3D XPoint的未来交付形式?
尽管英特尔公司必然会通过NVMe在存储领域推动3D XPoint的普及,但我猜测美光方面可能会选取更接近于内存定位的解决方案——因为美光毕竟是一家内存供应商,而不仅仅属于存储产品厂商。目前已经得到证明的是,3D XPoint确实可以作为内存使用并存储应用程序,因为该项技术具备bit寻址能力且可以在一定程度上实现等同于DRAM的运作方式。将3D XPoint进一步贴近CPU并通过DDR4接口实现对接,不仅能够最大程度发挥其性能表现,同时也可消除由PCIe带来的某些瓶颈。目前已经有众多基于NAND的产品遵循这一思路,包括SanDisk公司的ULLtraDIMM,外加JEDEC几个月前发布的DDR4 NVDIMM标准)这是一套用于弥合DRAM与SSD间性能空白的新型标准集。由于缺少NVMe这类标准化软件接口选项,NVDIMM目前仍然需要以驱动器的形式投入实际使用。而我坚信3D XPoint将成为推动NVDIMM进入市场的最佳技术选项,而这也将为美光带来可观的经济收益。
实际应用
3D XPoint的实际用例拥有非常光明的潜在发展空间,而英特尔与美光也认定这项技术将为各类新型应用程序的出现打开大门。纵观整个计算行业,此前曾经出现过多种高速非易失性内存技术——磁芯存储器就是最具代表性的传统方案——因此这一领域还残留着部分早期技术成果以及基础性研究项目。不过由于磁芯存储器早在大部分读者出生之前就已经过时,现代计算业界开发出了作为当前规范的高速DRAM与低速永久性存储技术。结果就是,尽管潜在应用选项已经非常丰富,但计算科学当中仍有大量尚未被探索的区域。
就基于3D XPoint的产品来讲,其最为立竿见影的应用方式就是在DRAM与SSD之间充当新的存储层。在计算科学发展的历史长河当中,存储与处理器之间的其它层级一直在不断出现——芯片内多级缓存、芯片外缓存、以及SSD缓存等等——而3D XPoint内存将充当这一体系当中的另一种新型存储介质,从而弥合DRAM与现有高速非易失性存储方案之间的空白区域。通过将3D XPoint作为另一种缓存层,这项技术将被应用于未来的高速应用程序当中,从而克服目前内存容量或者存储延迟给这类应用造成的拖累。
传统存储结构图(图片来源:哈佛大学Tommy MacWilliam)
考虑到3D XPoint产品的成本定位,其初步应用预计将会出现在企业级市场当中。企业用户需要大量使用各个层级的存储资源,从而帮助容量相对较低的DRAM实现性能均衡调整。拥有特定用途的数据库服务器需要经过妥善的缓存处理,而使用3D XPoint替代DRAM承载下一代数据库系统也可谓顺理成章。由于3D XPoint的非易失特性,我们甚至可以将其作为专用缓存——也就是说,其中的内容不需要存在于更低级的存储层当中——这将有效帮助基础设施削减运行负担。在这种情况下,数据库系统将只需要在数据被3D XPoint缓存排除出去之后将对应内容写入至SSD或者其它低级存储层当中,而对于经过严格调试的数据库来说、这样的情况将非常罕见。
大部分缓存层的固有优势都能够作用于其它偏重存储的服务器类型,不过我认为数据库是其中受益最为明显的用例场景。也许未来还将有更多更具吸引力的3D XPoint服务器支持方式出现,并逐步被大众所广泛接受。英特尔与美光目前正积极强调该技术在“大型科学”项目体系中的作用,其中包括大型强子对撞机、数据产出量极为惊人的泰坦超级计算机以及其它任何将数据处理与数据供给作为主要设计考量的项目及系统。任何一种分析机制都能够通过让各个处理器以内存方式访问与SSD容量级别等同的数据池的方式实现处理效率提升。
不过问题在于,相关企业仍然需要投入大量资源及研究力量来找到最合适的用途。这种访问速度及存储容量层面的革新不仅能够让计算机的运行速度更快,同时也能够从根本上转变算法的基本原理及设计思路。正如科学家们需要认真考量GPU在大型并发(及高延迟)处理任务当中的作用,3D XPoint的全面推广也需要有能够高效利用数据直接访问能力的新型算法加以配合。
与此同时,我认为金融行业应该也会率先加入到这方面的探索中来,因为他们立足于高度竞争且利润丰厚的业务领域,所以更倾向于尝试新型技术以提升自己的市场优势。从这个角度出发,3D XPoint所能带来的速度提升效果并不明显——毕竟此类工作负载已经被广泛交由内存池负责打理——但其仍然能够帮助从业人员利用模拟方案针对规模更大的数据集进行高效处理与分析。
至于在消费级领域,同样的原则同样适用于新型缓存层的介入,不过我不太确定这类市场是否会像企业用户那样积极在早期阶段加以采纳。考虑到3D XPoint产品的最终成本以及容量水平,大部分消费者对于价格要比专业用户更加敏感。在消费级领域,我们确实见到了相当一部分基于NAND技术的驱动器产品,但大多数使用者仍然坚持同时使用SSD与传统机械磁盘,甚至继续单纯使用后者。消费级用户也不愿为高端SSD产品的溢价买单,亦不太可能拥有足够的资金来购置高容量SSD方案。

不过如果着眼于游戏领域,我发现3D XPoint可能会拥有一部分施展空间,因为目前游戏已经成为消费级工作负载当中的一类特例。总体而言,我们都希望能够更快速地访问游戏资源,因为这些资源必须定期访问而且会对游戏的分段执行产生重要影响。不过这部分资源本身并不具备易失性——游戏当中只有一小部分工作集属于易失性数据,主要包括角色位置、AI决策树以及游戏状态等等。除此之外,其它部分都属于静态数据,具体包括模型、场景几何体以及纹理等。3D XPoint的速度表现足以取代内存承载这些数据,而数据本身的非易失性也保证了其不会过度消耗3D XPoint的全盘写入次数。在这种情况下,与DRAM相比较的写入性能短板也将被很好地掩藏起来。
不过实际情况还是要看这项技术的具体使用成本;如果其成本足够低廉,那么容量在50到100 GB的产品将可以被纳入游戏主机或者PC设备,从而帮助玩家将游戏的大部分内容存储在3D XPoint内存当中,最终实现载入速度加快、数据处理时间需求降低以及游戏状态设置提速等等。这一点对于游戏主机而言尤为重要,特别是考虑到目前大多数游戏机都在使用传统机械磁盘承载数据,这意味着游戏启动或者不同游戏切换时需要调用大量内存。相比之下,目前高端PC设备上的高容量DRAM已经能够很好地解决这个问题。
最后但同样重要的是,3D XPoint有可能被作为DRAM的替代性方案。相对于DRAM来讲,3D XPoint的使用寿命较为有限,这也是比拼当中的致命短板,不过我认为更大的问题还是来自整体传输带宽。就目前来看,3D XPoint已经逐步开始进行量产,而DRAM技术则应该会随着速度更快的下一代DDR4技术以及HBM的广泛普及而迎来新一轮升级。考虑到未来几代HBM已经在朝着每秒1 TB甚至更高传输能力进军,3D XPoint几乎没有办法在这方面与高带宽DRAM解决方案相抗衡。因此,任何关于DRAM即将消亡的断言恐怕都还为时尚早。

物联网与嵌入式,3D XPoint能否在这里一展拳脚?
不过值得一提的是,虽然3D XPoint不太可能在全部应用领域彻底取代DRAM,但相信它仍然能够寻找合适的区域将DRAM一军——特别是在DRAM主要依靠带宽与延迟等比较优势所立足的市场当中。举例来说,利用3D XPoint在嵌入式应用中取代DRAM就非常可行——很多嵌入式用例根本不需要可观的传输带宽或者低延迟水平。在这方面,传统NAND的表现显然更好——当然,需要强调的还有智能手机业务领域。如果3D XPoint芯片能够在尺寸与成本方面进一步削减,那么这项技术相信能够在低性能设备这一广阔的市场空间当中给DRAM带来沉重的一击。不过我得再说一次,那些需要速度全开且极低延迟的高性能硬件平台仍然将由DRAM一家独大。
总结陈词
关于3D XPoint,还有很多值得探讨的内容。自从1989年NAND诞生以及过去几十年DRAM与NAND不断发展演变以来,整个内存行业似乎一直没能拿出什么惊人的成果——但如今,3D XPoint绝对算得上一种全新内存类型。它速度很快、耐用性好、具备可扩展能力及非易失特性,这相当于同样占据了DRAM与NAND双方的主要优势。它非常适合介于DRAM及NAND之间的利基市场,而且坐拥两大主流传统方案固有优势的能力也使其成为一套前所未见的重要技术成果。

此次公告的重要意义不仅在于推出了一种新型内存技术,同时也是因为其具体成果将在未来几年内开始投入量产。英特尔与美光双方已经成为将一项技术概念从实验室中转移到了代工流水线,而且其核心实质可谓迥异于目前的任何一种新型半导体技术。相当一部分能够在实验室中确切起效的技术概念都在批量生产当中遭遇障碍,但英特尔与美光利用巨额投资开发出了新型材料化合物以及周边技术,从而让3D XPoint顺利转化为一款实际产品。我们将高度关注其它DRAM与NAND供应商会就此作出何种反应,毕竟在内存行业当中,没有任何一家厂商愿意坐视自己的竞争对手开发出一套让人完全摸不着头脑的新方案。
不过,3D XPoint显然并不算是DRAM或者NAND的真正继任者,而英特尔与美光也并不打算为其设定这样的角色。DRAM将继续在高性能应用市场保持着延迟与使用寿命角度的王者地位。我们的早期成本分析也显示,3D XPoint还无法达到平面NAND、更遑论3D NAND的存储密度。不过由于具备横向与纵向伸展能力,相信3D XPoint终将有一天彻底取代3D NAND的历史地位。
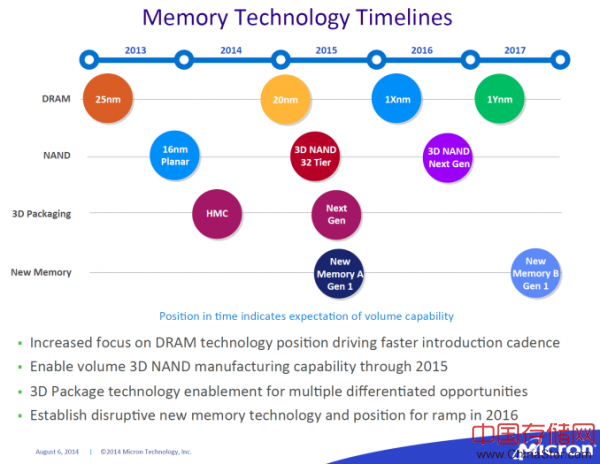
展望更遥远的未来,3D XPoint并不是英特尔与美光拿出的惟一一席技术盛宴。如果一切按照计划顺利推进,那么我们应该会在未来两年内见识到双方打造的另一款新型内存技术方案。由于3D XPoint似乎更适合取代3D NAND,那么第二项新技术也许正是DRAM的致命克星。
总而言之,提早评估3D XPoint在未来可能实现的应用场景是项重要的工作,因为这是一项前所未有的崭新技术。不夸张地讲,我甚至认为3D XPoint有可能给现代计算机体系结构及运作方式带来根本性转变——当然,这种转型不会在一夜之间发生,而且很可能还要面临其它厂商竞争技术带来的挑战。不过可以肯定的是,英特尔与美光双方已经在即将在明年拉开序幕的内存与计算新时代中占据了先发优势。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。